For the financial sector, as well as for telecommunications, advertising and retail industries, and even government bodies, making sense of information collected from various sources and translating it into tangible results is of the utmost priority.
What can be done at the database level is but one element of the process, but its impact is quite significant, as the ways in which an organization can store and manage data vary greatly.
Firstly, it is important to differentiate between types of database management systems (DBMS).
NoSQL is the future

Born in the 1970s, Structured Query Language (SQL) databases, by definition, are queried in standardized code. Most traditional DBMS are based on SQL, and follow the relational model, meaning they are very highly structured in their querying specifications.
What’s more, until now, most databases have been centralized, stored and maintained in a single location, typically a desktop server or a mainframe.
One of the most popular examples of an SQL database is MySQL, an open-source relational DBMS implementation for the web, developed in 1995 by Michael ‘Monty’ Widenius and widely adopted among Internet giants.
More recently, we have seen the emergence of a NoSQL model (which is misleadingly short for ‘Not only SQL’). These databases are non-relational - meaning they are structured in a way that supports many-to-many relations between datasets, and can be scaled without the need for hardware upgrades.
At the same time, more and more companies have shifted to a distributed approach, which allows them to run replicated databases in a number of geographically separate locations.
The modern database must be scalable, decentralized, and allow for the aggregation of disparate data types. Thus, relational databases have lost some of their appeal, and NoSQL databases have emerged from the fringes of the industry to gain a significant share of the market.
In fact, the NoSQL market is expected to be worth $4.2bn by 2020, according to Allied Market Research. In the past decade, an influx of these databases have replaced legacy engines, responding to a new operational model. Popular examples include MongoDB, Redis, HBase, MarkLogic and Cassandra.
More data is collected today than ever before, and as a consequence, speed is another characteristic on which DBMS providers are expected to improve. For this reason, another departure from tradition has been a rapid increase in the use of in-memory databases.
The advent of in-memory DBMS
Whereas before, on-disk infrastructure required interaction between separate data warehouses (Teradata, Informatica, Redshift) and operational databases (Hadoop, Cloudera), with in-memory, it is possible to consolidate analytics, machine learning, AI and operations in a single place.
By relying exclusively on system memory, one eliminates the need for disk I/O to query or update data, and additional cache copies are no longer necessary.
The main downside of in-memory databases is that they were historically limited by the high cost of RAM. As the price of memory has decreased, in-memory databases have grown in popularity, and the expectation of real-time analytics has gained prevalence.
Being between 10 and 100 times faster than disk-based DBMS (a difference of milliseconds), in-memory systems may bring solutions to problems posed by IoT data analysis, autonomous vehicles, modern retail platforms, transaction processing and fraud detection.
And indeed, according to research firm Markets and Markets, the in-memory market could reach a value of $13.23bn in 2018. Major companies traditionally working on disk have developed their own in-memory systems, including Oracle, Microsoft and SAP.
On a visit to the Silicon Valley in February as part of the IT Press Tour, DCD met several DBMS companies, all of which had varying approaches to database technology.
Founded in 2009, Aerospike’s flash-optimized, NoSQL database connects directly to the application database, using hybrid memory architecture (combining DRAM and SSDs) and promising to deliver low latency for applications at scale. The open source key-value store system was designed to provide a solution for latency-critical applications, both in real-time transaction processing and real-time analytics - which ordinarily rely on different databases, for different reasons.
One of the main differences between the two, co-founder and CTO Brian Bulkowski explained, is that transactions require a balance of writes and reads, whereas analytics tends to be very read-intensive.
Srini Srinivasan, Aerospike’s co-founder and chief development officer, added that businesses tend to use different technologies for systems of record, dealing with telco customer data, reservations and financial risk, where consistency and accuracy are key, and systems of engagement, such as real-time bidding, cyber security and fraud detection, in which performance and availability are top priorities.
By effectively replacing the cache layer, and thanks to the combined use of SSDs and RAM, Aerospike says it can ensure low latency and high throughput. What’s more, its clustering capabilities can meet the needs of distributed applications too.
To improve the disk I/O, Aerospike places indexes in DRAM rather than on SSDs; it optimizes the network by colocating user and index data on the same node to avoid excessive hops between them, automates routing of client requests and balances workloads automatically. Finally, it offers multi-threading and parallel processing across multiple SSDs to facilitate scaling.
For Bulkowski, the company’s mission is to bring the proprietary technologies used by Internet giants - which he is adamant are similar to Aerospike’s product - to real-time, big data applications.
Emphasis on speed and scale are two priorities shared by Foster-city based GridGain, whose in-memory software can either sit between the application and the database (or data lake), or be deployed as an in-memory SQL database.
GridGain was built to support transactional and analytical applications, and is based on the Apache Ignite open source project, which the company created (and to which it is still the main contributor). Like Aerospike, it eliminates the need to separate operations from analytics and machine learning capabilities, bridging the gap between a data warehouse and an operational database.
As a consequence, Abe Kleinfeld, the company’s president and CEO explained, the system is free from data integration and feedback loop interactions. All capabilities are held in a unified, in-memory datastore, and the platform has a unified API - meaning it can aggregate data in different formats and structures.
The in-memory system has proved popular with financial services, and the company doubled its revenue in the past year, boasting clients such as ING, Société Générale, Apple, Huawei and Microsoft.
GridGain’s biggest project by a stretch was a 2,150 Teraflop cluster totaling 56,000 CPUs and 1536TB of memory, commissioned by Sberbank of Russia.
Both Aerospike and GridGain focus on a “scaling out” approach, increasing the node count to increase the database performance.
A GPU-accelerated database

{kind=link}
{kind=link}
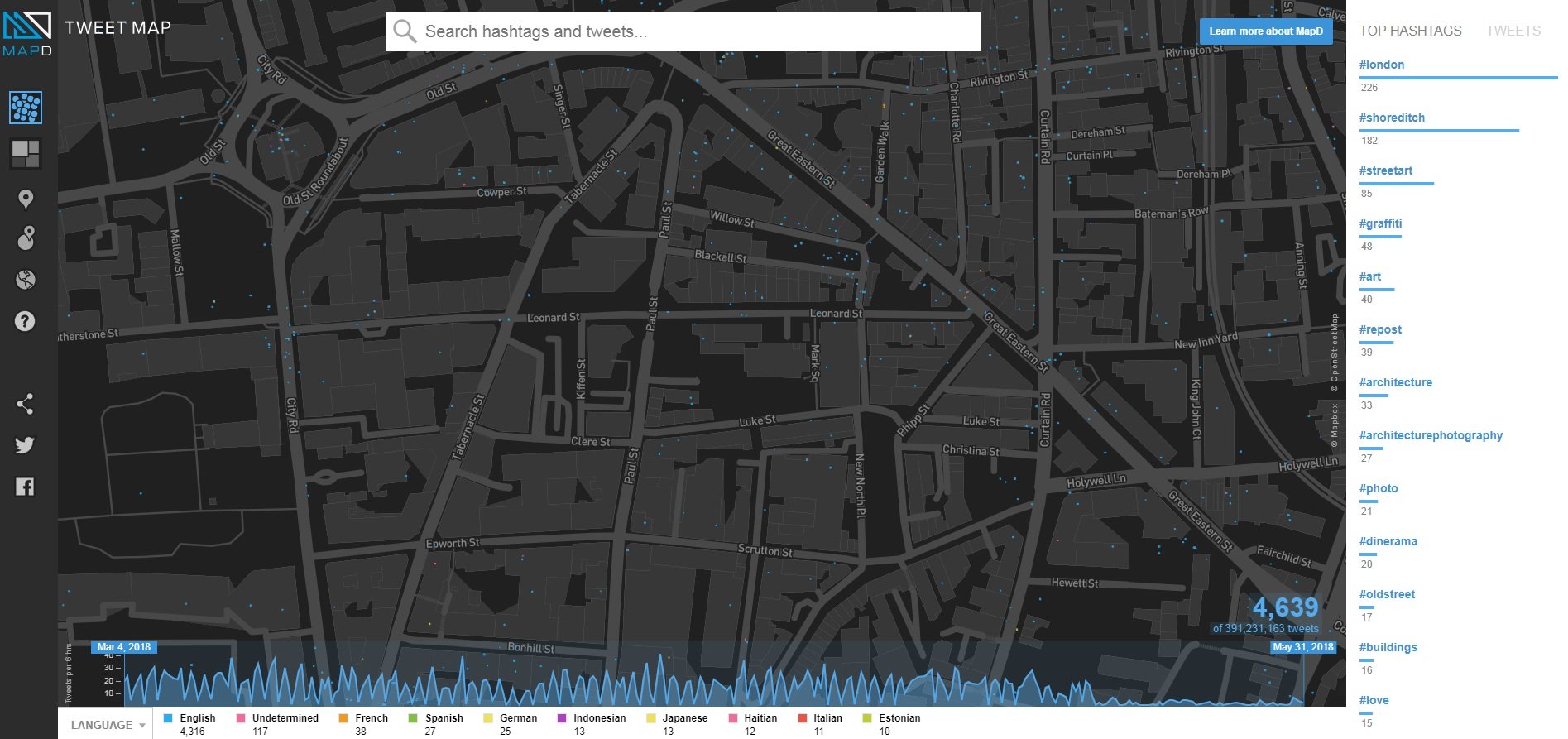
MapD chose to improve the performance of each individual node instead, with an open-source in-memory database which runs on anything from one to 16 GPUs per server.
It was a desire to visualize and interact with data in real-time that gave birth to MapD, and two of its products which go hand in hand: MapD Core, the GPU-accelerated SQL database, and MapD Immerse, a web-based visual analytics platform that sits atop the SQL engine and can render billions of data records in a single compressed image. The engine requires no pre-indexing or pre-aggregation: everything is done in real-time, over potentially billions of rows.
Restricted to just structured data, the company’s CEO and co-founder, Todd Mostak said, MapD Core isn’t as versatile as some of its NoSQL contemporaries - but instead of a replacement for data warehouses, it markets itself as “a sidecar.”
“We’re like a hot cache on your store record. That could be pulling data out of a data lake or a Hadoop system, that could be pulling data out of a traditional data warehouse like Teradata.”
“You can hit third-party business intelligence tools, we have a nice DBI-compliant Python connector, and of course a lot of our customers leverage MapD Immerse. Even though it’s not as feature complete as Tableau, it does a lot for very agile exploration of very large datasets through the SQL and rendering capabilities.”
The system finds its uses in model generation for fraud, risk and anomaly detection, geo-analytics and cyber security, real-time fleet management and incentive-based insurance.
In 2014, MapD won Nvidia’s $100K Early Stage Challenge, a prize awarded annually to the best start-up that utilizes GPUs, and the chip manufacturer has since participated in all three of the company’s funding rounds.
MapD recently launched a software-as-a-service (SaaS) offering, which runs on Nvidia GPUs across data centers “from the leading cloud infrastructure providers,” with automated provisioning, optimization, support and upgrades.
Together with partners Continuum Analytics and H2O.ai, MapD recently founded the GPU Open Analytics Initiative (GOAI) to integrate its platform with other GPU-based projects.
The consortium’s end-game is to enable the combined use of GPU-based analytics tools, starting with the framework for GPU-native data formats and APIs.
“The idea when we all got together was that we’re all running on the GPU, so let’s have a zero-copy framework such that we can pass data seamlessly through these different processes without the overhead of marshaling again or going through the CPU,” Mostak explained.
This article appeared in the April/May issue of DCD Magazine. Subscribe to the digital and print editions here: