
One of the findings of Uptime Institute’s recently published report Annual outage analysis 2020 is that the most serious categories of outages — those that cause a significant disruption in services — are becoming more severe and more costly. This isn’t entirely surprising: individuals and businesses alike are becoming ever more dependent on IT, and it is becoming harder to replicate or replace an IT service with a manual system.
But one of the findings raises both red flags and questions: Setting aside those that were partial and incidental (which had minimal impact), publicly reported outages over the past three years appear to be getting longer. And this, in turn, is likely to be one of the reasons why the costs and severity of outages have been rising.
{kind=link}
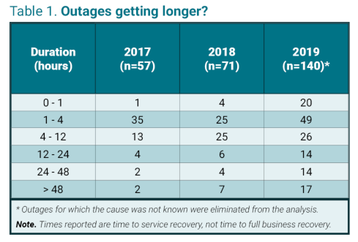
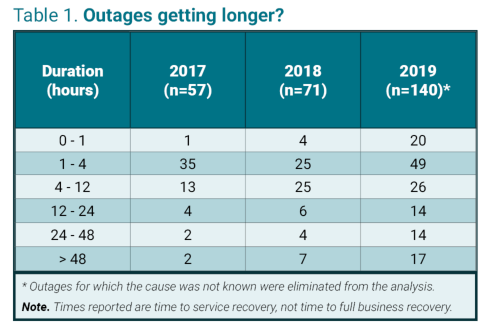
The table shows the numbers of publicly reported outages collected by Uptime Institute in the years 2017-2019, except for those that did not have a financial or customer impact or those for which there was no known cause. The figures show outages are on the rise. This is due to a number of factors, including greater deployment of IT services and better reporting. But they also show a tilt in the data towards longer outages — especially those that lasted more than 48 hours. (This is true even though one of the biggest causes of lengthy outages — ransomware — was excluded from our sample.)
The outage times reported are until full IT service recovery, not business recovery — and business recovery may take longer, since it may take longer, for example, to move aircraft back to where they are supposed to be, or to deal with backlogs in insurance claims.
The trend to longer outages is not dramatic, but it is real and it is concerning, because a 48-hour interruption can be lethal for many organizations.
Why is it happening? Complexity and interdependency of IT systems and greater dependency on software and data are very likely to be big reasons. For example, Uptime’s Institute’s research shows that fewer big outages are caused by power failure in the data center and more by IT systems configuration now than in the past. While resolving facility engineering issues may not be easy, it is usually a relatively predictable matter: failures are often binary, and very often recovery processes have been drilled into the operators and spare parts are kept at hand. Software, data integrity and damaged/interrupted cross-organizational business processes, however, can be much more difficult issues to resolve or sometimes even to diagnose — and these types of failure are becoming much more common (and yes, sometimes they are triggered by a power failure). Furthermore, because failures can be partial, files may become out of sync or even be corrupted.
There are lessons to be drawn. The biggest is that the resiliency regimes that facilities staff have lived by for three decades or more need to be extended and integrated into IT and DevOps and fully supported and invested in by management. Another is that while disaster recovery may be slowly disappearing as a type of commercial backup service, the principles of vigilance, recovery, and fail over – especially when under stress – are more important than ever.
The full report Annual outage analysis 2020 is available to members of the Uptime Institute Network here.