
Across data centers, the accelerating adoption of cloud infrastructure and services is driving the need for more bandwidth, faster speeds and lower latency performance. Regardless of your facility’s market or focus, you need to consider the changes in your enterprise or cloud architecture that will be necessary to support the new requirements.
That means understanding the trends driving the adoption of cloud infrastructure and services, as well as the emerging infrastructure technologies that will enable you to address the new requirements.
You may think that being at 10Gb or 100Gb today means the transition to 400Gb is a long way off. But if you add up the number of 10Gb (or faster) ports you're responsible for supporting, you'll see that the need to move to 400Gb and beyond is really not that far away. Here are a few things to think about as you plan for the future.
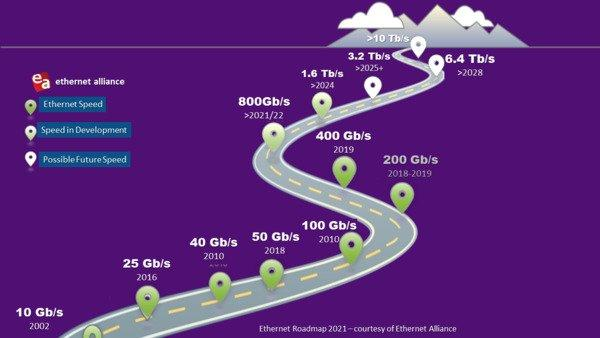
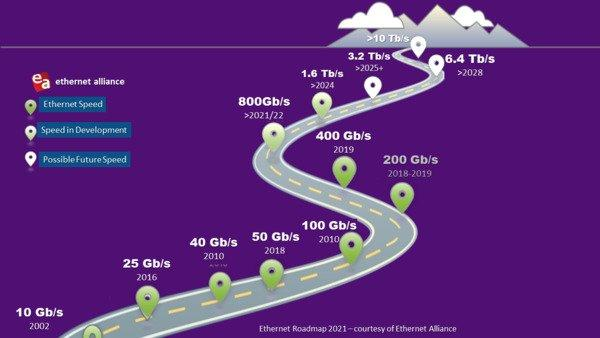
As data center managers look to the future, the signs of a cloud-based (r)evolution are everywhere.
- More high-performance virtualized servers;
- Higher bandwidth and lower latency;
- Faster switch-to-server connections;
- Higher uplink/backbone speeds;
- Rapid expansion capabilities.
Supporting these changes begins with enabling higher lane speeds. The progression from 25 to 50 to 100Gb and above has become more common and is beginning to replace the 1/10/40Gb migration path. Within the cloud itself, the hardware is changing as well. We've moved from multiple disparate networks typical in a legacy data center, to more virtualization using pooled hardware and software-driven management. This virtualization is driving the need to route application access and activity in the fastest possible way, forcing many network managers to ask, “How do I design my infrastructure to support these cloud-first applications?”
We see a few basic building blocks being employed to help define a clear path from 10Gb to 25Gb to 50Gb and 100Gb. Many network managers are using more direct machine-to-machine connections, reducing latency by reducing the number of switches between them. Applications rely on many machines working together, and the networks that connect them must evolve to continue to meet the service and capacity demands while improving overall power efficiency.
Connecting more machines directly together using ‘high radix’ switches means fewer switches (and lower costs and power consumption). As radix increases, more machines can be connected to a single switch without having to worry about switch capacity or latency. It’s a more precise way to look at switch capacity. Switch connection speeds are also increasingly enabled by switch ASICs with higher serialized/de-serialized (SerDes) speeds. Taken together, this forms a comprehensive strategy to improve the operational capacity and efficiency of cloud-scale data centers.
Transceivers, connectors and chips
The current SFP, SFP+ or QSFP+ optics are sufficient to enable 200Gb link speeds. However, making the jump to 400Gb will require doubling the density of the transceivers. This is where QSFP-Double Density (QSFP-DD) and octal (2 times a quad) small form factor pluggable (OSFP) technologies come into play.
The QSFP-DD transceivers are backwards compatible with existing QSFP ports. They link to existing optic modules, QSFP+ (40Gb), QSFP28 (100Gb) and QSFP56 (200Gb), for example.
OSFP, like the QSFP-DD optics, enables use of eight lanes versus four. Both types of modules enable you to fit 32 ports in a 1RU panel. To support backwards compatibility, the OSFP requires an OSFP-to-QSFP adapter. A key difference between the two technologies is that the OSFP targets higher power applications (<15W*) than QSFP-DD (<12W*). The MSAs mention different optical connection options: LC, mini-LC, MPO 8, 12, 16, SN, MDC and CS connectors could be chosen depending on the application supported.
The variety of connector technology options provides more ways to break out and distribute the additional capacity that octal modules carry. The 12-fiber MPO (sometimes used with only eight fibers) was able to support six lanes with two fibers each. Many applications used only four lanes, however, such as the 40GBase-SR4 with eight fibers. Octal modules have eight lanes and are able to support eight machine connections versus four with the QSFP modules.
Switches are evolving to provide more lanes at higher speeds, while reducing the cost and power of networks. Octal modules enable these additional links to be connected through the 32-port space of a 1U switch. Maintaining the higher radix is accomplished by using lane breakout from the optic module. MPO16 and 16 fiber cabling systems are ideally suited to support this new network paradigm.
Other connectors worth looking into are the SN and MDC. The SN is a very small form factor (VSFF) duplex optical fiber connector. It is intended to serve hyperscale, edge, enterprise and colocation data center interconnect (DCI) applications. These connectors incorporate 1.25-mm ferrule technology and are targeted to provide more flexible breakout options for high-speed optical modules. The SN and MDC connectors can provide four duplex connections to a quad or octal transceiver module. However, they are not intermateable, and both connectors are hoping to become the standard path to VSFF. The early applications for these connectors are primarily in this optic module breakout application. The ultimate question will be which transceivers are available with which connectors in the future.

Of course, there are no limits to the demand for bandwidth. Currently, the limiting factor isn’t how much you can plug into the front of the switch but how much capacity the chipset inside can deliver. Higher radix combines with higher SERDES speeds to net higher capacity. The typical approach in and around 2015 for supporting 100Gb applications used 128 - 25Gb lanes, yielding 3.2Tb switch capacity. Getting to 400Gb required increasing the ASIC to 256 50Gb lanes, yielding 12.8Tb of switch capacity. The next progression – 256 100Gb lanes – takes us to 25.6Tbs. Future plans are being considered to increase the lane speeds to 200Gb. That is a difficult task, which will take a few years to perfect.
Adapting the physical layer cabling and designs
Of course, the glue holding everything in your network together is the physical layer cabling. We could easily devote an entire series to this topic alone; instead, here are a few highlights.
To enlarge their pipes, data centers are going beyond the traditional duplex applications. Networks are deploying more 4-pair, 8-pair and 16-pair configurations, depending on the applications they support. They are using both single-mode and multimode optics, duplex WDM and parallel cabling combined to support a variety of network topologies. The objective is increased capacity and efficiency. The optimal solution varies, but we have a lot of tools at our disposal. The hard part is charting a course that leads from your existing state (often with a very large installed base) to something that might be two steps ahead with different network topologies, connector types and cabling modules, like 16f, and so on.
Meanwhile, flattened, fiber-dense, spine-leaf configurations are designed for lower latency east-west traffic. The trend among data centers and larger enterprise networks is toward a fiber-dense mesh architecture that optimizes east-west traffic (often 10-times north-south traffic) – still a spine-leaf orientation, but with fewer network layers and often with a view to higher server attachment speeds.
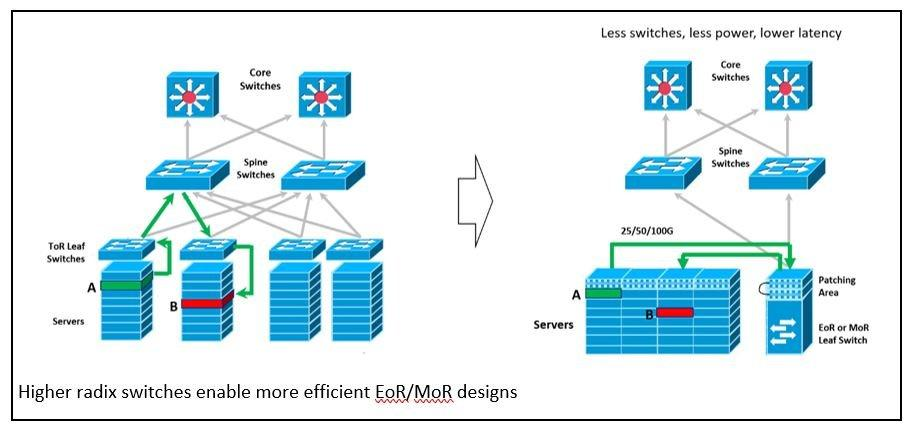
The continued evolution of mesh-type architectures isn’t all that newsworthy. When you add the benefits of higher radix switches, however, the effects are significant. In most spine-leaf networks today, the leaf switches feed ToR switches positioned at the top of each server rack. This design was optimal for low radix switches operating at lower server attachment speeds. A ToR switch would provide about a rack’s worth of server connections – with short low-cost connections between the server and the ToR switch.
Moving to higher radix switches means even though you’re still using 32 ports, there are twice as many lanes available to attach servers. This provides an intriguing opportunity. With the higher radix switches, you can now migrate to a design in which multiple ToR leaf switches are replaced by fewer leaf switches located either end-of-row (EoR) or middle-of-row (MoR). Eliminating some of the switches means fewer hops, lower latency and more efficient design.
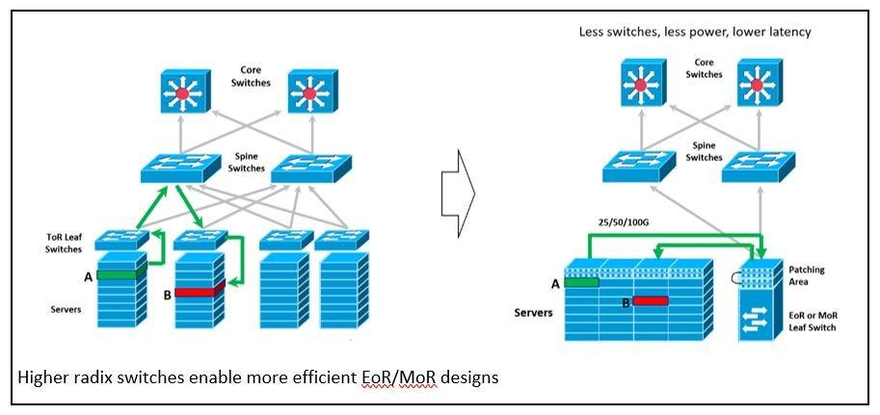
The ideal solution for this application will require that the radix be maintained with eight connections per optic module. Maintaining lower costs for this option is enabled by using less costly MM optics, as well as new 400GSR8 application support for eight 50Gb server connections over 100m of OM4 cabling.
Looking ahead, development in the 802.3db is aiming to double the lane speed to 100Gb over this same MMF infrastructure. This is ideal for higher density AI/ML pods, which absolutely require much higher server network speeds but do not need longer network links that would require higher cost SM optics.
The conversations you should be having and with whom
Admittedly, there is a long list of things to consider regarding a high-speed migration to 400Gb and beyond. The question is, what should you be doing?
A great first step is to take stock of what you’ve got in your network today. How is it currently designed? For example, you've got patch panels and trunk cables between points, but what about the connections? Do your trunk cables have pins or not? Does the pin choice align with the transceivers you plan to use? Consider the transitions in the network. Are you using MPO-to-duplex, a single MPO to two MPOs? Without detailed information on the current state of your network, you won’t know what’s involved in adapting it for tomorrow’s applications.
Speaking of future applications, what does your organization’s technology roadmap look like? How much runway do you need to prepare your infrastructure to support the evolving speed and latency requirements? Do you have the right fiber counts and architecture?
These are all things you may already be considering, but who else is at the table? If you're on the network team, you need to be in dialogue with your counterparts on the infrastructure side. They can help you understand what’s installed, and you can alert them to future requirements and plans that may be further down the road.
Last but not least, it’s never too early to bring in outside experts who can give you a fresh pair of eyes and a different perspective. While nobody knows your needs better than you, an independent expert is more likely to have a better handle on existing and emerging technologies, design trends and best practices.
More from CommScope on trends and technologies driving the data center evolution to 400G and beyond.



{kind=link}
{kind=link}
{kind=link}