

Last year I had the privilege of joining my son, who is serving in the US Navy, on board the USS Nevada SSBN-733 nuclear submarine. That experience was marked by fatherly pride and a deepening respect for the brave crew. However, I also couldn’t help but pay attention to the practices and procedures that ensure these complex machines are always 100 percent battle-ready.
In 2008, nuclear scientist Romney Beecher Duffey and aviation regulator John Walton Saull published Managing Risk: The Human Element. The book explores the challenge of managing complex homo-machine systems (HMS) and comes to the conclusion that any complex HMS will fail within 150,000 to 200,000 hours.

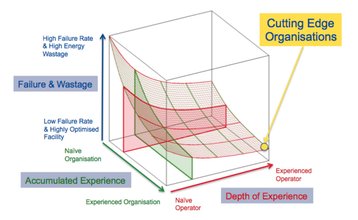
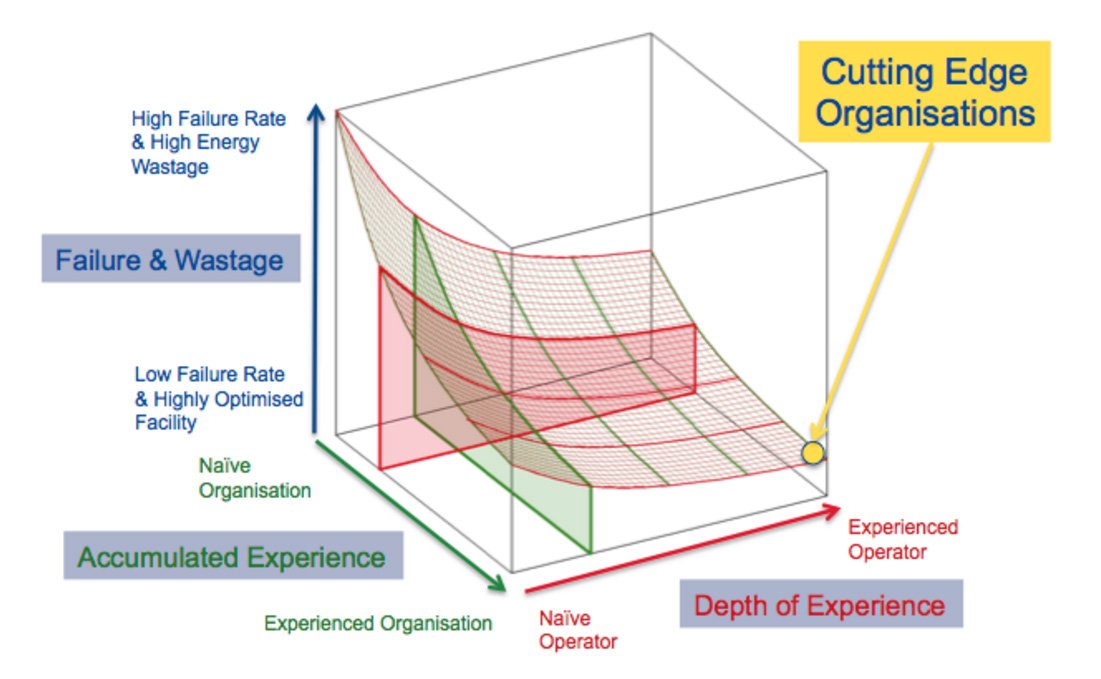
Experience counters failures
That sounds like bad news, but the organization and the operators of an HMS will accumulate experience that reduces the rate of failures. Duffey and Saull illustrated this with the Universal Learning Curve (below), a graph that moves lower as experience is gained. Effective organizations such as the US Navy combine organizational experience with operator experience to minimize failure.
The obvious lesson for the data center industry is that a complex HMS will fail. We need policies and procedures to operate our facilities knowing an event will occur, managing the environment accordingly to keep the facility operational. We also need to use design to make it resilient to external and internal fault events, and employ best practices, such as proper factory witness testing and commissioning, to eliminate the most nascent failures.
But the question my experience on the USS Nevada left me wrestling with was whether our industry’s push for higher efficiency and reduced costs has inadvertently compromised overall availability, reliability and resiliency due to a lack of understanding of the Universal Learning Curve.
{kind=link}
{kind=link}
{kind=link}
The risk of chasing PUE
For many years we designed and operated Tier IV facilities using a 2 (N+1) architecture and sound operational practices lifted in large part from the military. With operational learning, real-world feedback, and knowledge-sharing within the consulting engineering community and critical infrastructure OEMs, we moved down the curve and, for the most part, operated without single-event outages. Then we started chasing power usage effectiveness (PUE), and now data center outages are making headlines almost every week.
The kicker is that the two aren’t mutually exclusive. Switch operates several Tier IV, classic 2 (N+1) data centers with annual PUEs below 1.3. Infrastructure technology has improved to the point where numerous highly reliable Tier IV designs are now capable of PUEs below 1.2 in certain climates.
New architectures might appear on paper to have a calculated reliability that is ‘close enough’ to what we want to be worth the risk. But that ‘paper’ doesn’t tell the whole story. Using new components, infrastructure, systems and operational practices move the entire HMS so far back up the curve that mere factory tests are not sufficient to mitigate risk.
Quantify the cost of failure
To achieve both reliability and efficiency, we need a better understanding of the cost of ownership and the cost of failure. The Ponemon Institute in Michigan has already quantified downtime costs for various industries, and Emerson Network Power is working with Ponemon to quantify data center ownership costs based on facility size. What we are finding is that “plant” costs (building and infrastructure), when amortized over a typical data center lifecycle, represent a small percentage of total costs for all data center sizes.
Has our industry’s push for higher efficiency and reduced costs inadvertently compromised overall availability, reliability and resiliency?
Try to work with consulting engineers and infrastructure partners on design, construction and startup to help improve your organizational experience. These partners can also be valuable resources in helping you develop learning and skills for your facility personnel, creating the training and operating practices for smooth, predictable operations and continued uptime. Remember, Murphy was an optimist!
Jack Pouchet is VP of market development at Emerson Network Power
This article first appeared in the September issue of DatacenterDynamics