
Meta ha brindado información sobre el diseño de su nuevo centro de datos, que incluye enfriamiento por aire y líquido para cargas de trabajo estándar y de alta densidad.
A fines del año pasado, DCD dio a conocer la noticia de que Meta estaba cancelando o pausando proyectos de centros de datos en pleno desarrollo en todo el mundo, ya que de repente cambió para admitir cargas de trabajo de inteligencia artificial en medio de un pivote generativo de IA.
Meta es un gran operador de centros de datos, una investigación de DCD en 2022 que encontró que su campus de Prineville era el centro de datos operativo más grande del mundo. Solo en el último trimestre, el gasto de capital de la empresa para centros de datos, servidores y oficinas alcanzó los 7.100 millones de dólares , y la empresa advirtió a los inversores que una construcción de IA resultaría costosa.
Centros de datos de última generación
La empresa necesitaba repensar cómo hace sus instalaciones después de apostar por las CPU y sus propios chips internos para manejar tanto las cargas de trabajo tradicionales como las de IA. Pero a medida que el uso de la IA se ha disparado y se ha convertido en un punto crítico de competencia para las grandes tecnologías, las CPU no han podido mantenerse al día.
Mientras tanto, el chip interno de Meta no cumplió con los objetivos internos y se descartó un lanzamiento planificado el año pasado.
Ahora, la compañía espera adoptar las GPU y ha hecho un nuevo intento con un chip interno. También ha presentado un chip interno para la transcodificación de video, similar al semiconductor Argos de YouTube.
"Estamos experimentando un crecimiento en la tecnología de inteligencia artificial, así que debemos asegurarnos de que nuestro centro de datos pueda adaptarse a algo que aún está evolucionando", dijo el director global de ingeniería estratégica del centro de datos de Meta, Alan Duong, en un evento de prensa.
"Y tenemos que escalarlo 4 veces, aproximadamente", añadió.
Duong señaló que la IA "hace que la innovación en el diseño del centro de datos sea realmente compleja", ya que la empresa tiene que equilibrar el diseño para las cargas de trabajo actuales con las necesidades desconocidas del futuro. "Por ejemplo, durante los próximos cuatro años, podemos ver un crecimiento de una vez y media a dos veces en el consumo de energía por acelerador, y aproximadamente una vez y media para la memoria de gran ancho de banda".
Meta espera comenzar la construcción del primero de sus centros de datos de próxima generación "hoy o este año", dijo Duong. "Si estamos comenzando con la construcción de ese centro de datos, para cuando terminemos, podríamos estar obsoletos [a menos que estemos preparados para el futuro]".
Es posible que el centro de datos deba admitir implementaciones de espacios en blanco drásticamente diferentes: "Dependiendo de lo que necesiten nuestros servicios y productos, podemos ver clústeres de escala más pequeña de 1.000 aceleradores a potencialmente 30.000 más para trabajos mucho más grandes. Cada una de estas configuraciones, así como el El acelerador que utilizamos requerirá un enfoque ligeramente diferente para los diseños de hardware y sistemas de red".
Para el entrenamiento de IA, los servidores están "construidos alrededor de aceleradores y el sistema de red operando como uno solo", continuó. "Esto también permite la eficiencia en nuestra implementación de fibra, porque necesitamos una fibra significativa para interconectar estos servidores. Por lo tanto, ubicarlos más juntos nos permitirá obtener algunas eficiencias allí".
Las GPU requieren mucha más energía que las CPU (y, por lo tanto, más refrigeración), algo que el diseño del centro de datos anterior de Meta no podía admitir.
"Estos servidores requerirán diferentes tipos de refrigeración", dijo Duong. Si bien las GPU de alta densidad necesitarán refrigeración líquida, Meta aún tendrá una gran cantidad de cargas de trabajo tradicionales que pueden existir en las CPU, que aún pueden usar refrigeración por aire.
La instalación en su conjunto utilizará refrigeración por agua, pero solo se utilizará para la unidad de tratamiento de aire en la mayoría de los servidores. En cambio, un número creciente de servidores de entrenamiento de IA obtendrán agua de una unidad de distribución de refrigeración y luego directamente al chip. Parte de esta infraestructura de refrigeración es USystems ColdLogik RDHx, según entiende DCD. Una imagen compartida con DCD parece mostrar algún tipo de enfriamiento por inmersión, pero Meta no lo mencionó durante su anuncio; DCD se comunicó con la compañía para obtener aclaraciones.

"Solo implementaremos un pequeño porcentaje de líquido para enfriar chips el primer día", dijo Duong. "Y lo ampliaremos según lo necesitemos. Esto significa una colocación y una planificación iniciales más complejas del rack; no hemos tenido que hacer eso en el pasado. Por lo tanto, este es un proceso muy complicado para nosotros, pero nos permite ahorrar algo de capital".
También admitió que "los requisitos de pruebas futuras para la refrigeración por aire y por agua no nos hacen ningún favor en cuanto a la eficiencia energética, la reducción de costos o la implementación más rápida de los centros de datos. Por lo tanto, tuvimos que hacer algunas concesiones a medida que avanzamos en el diseño".
Una compensación potencial es que la empresa utilizará menos generadores diésel y otra capacidad de recuperación física y, en su lugar, dependerá más de la capacidad de recuperación del software y algo de búfer de hardware. “Pero esto significa que vamos a asumir un riesgo desconocido asociado con el software para nuestras cargas de trabajo de IA”, dijo Duong. "Todavía estamos aprendiendo sobre eso, ya que estamos implementando esto a escala. Y a medida que aprendemos más, podríamos ajustar nuestra estrategia".
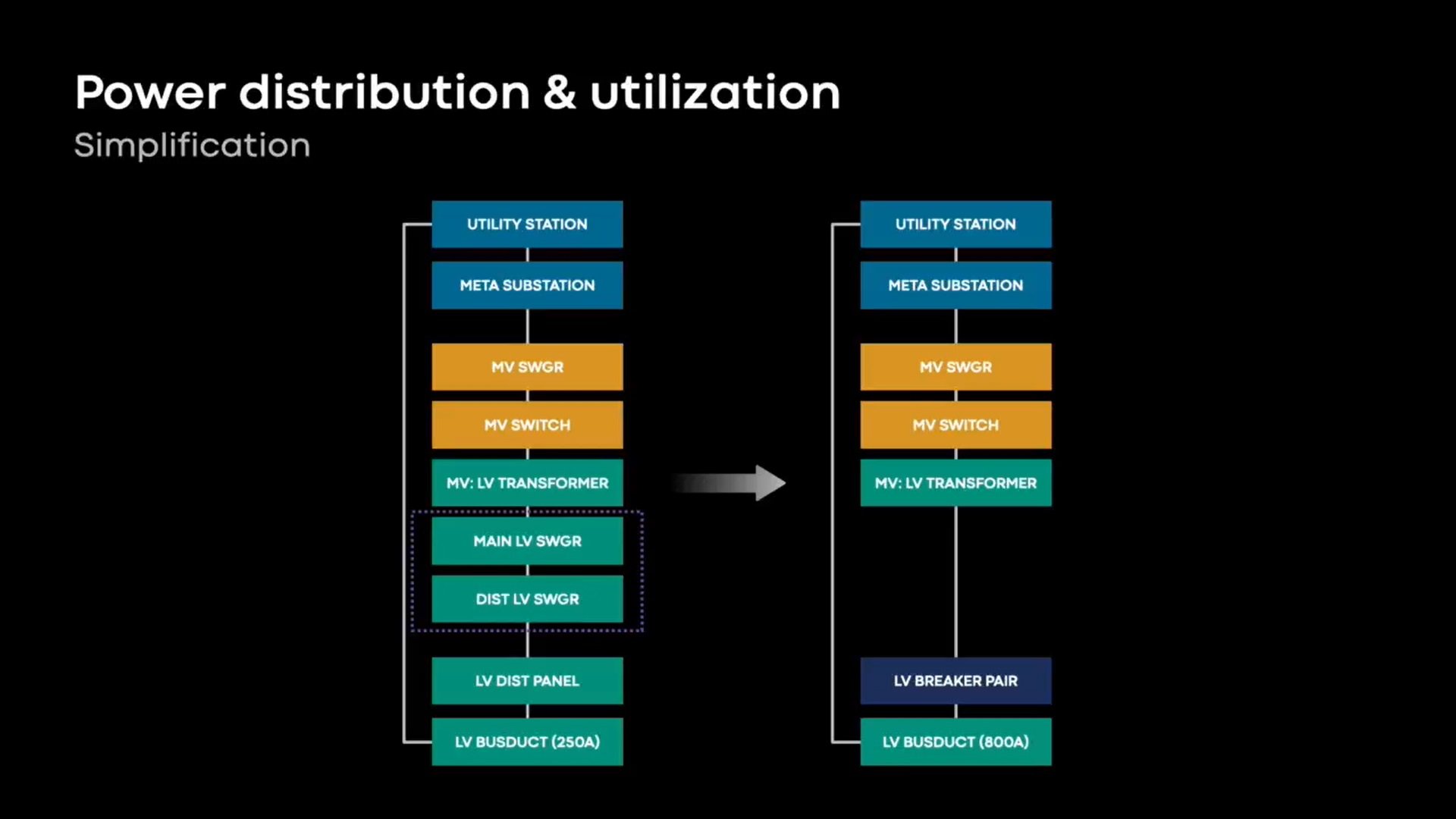
El nuevo diseño también acerca la infraestructura de energía al rack del servidor, dijo Duong. "Será más simple y más eficiente con nuestro nuevo diseño. Estamos eliminando tantos equipos como sea posible a través de nuestra cadena de distribución de energía... estamos eliminando el interruptor de bajo voltaje, que crea un cuello de botella en la capacidad.
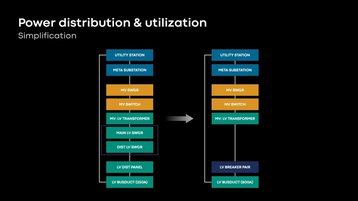
"Eliminar eso permite que el rack de servidores crezca en densidad en el futuro con modificaciones menores a nuestra infraestructura, y continúa permitiendo una mayor utilización de energía".
La compañía afirma que sus centros de datos actuales utilizan aproximadamente más del 70 por ciento de la energía que despliega, pero no dijo hasta dónde llegarán sus nuevos diseños.
En general, la empresa prevé que su centro de datos de última generación será un 31% más rentable. "Y podremos construirlo dos veces más rápido para una región completa, cuando se compara con nuestro centro de datos de generación actual", dijo Duong.
La supercomputadora de Meta
Fuera del diseño central para sus futuros centros de datos estándar, Meta ha operado el 'SuperCluster de investigación de IA' desde principios de 2022, en sí mismo una actualización de una supercomputadora anterior.
El RSC ahora se ha actualizado con casi 10.000 GPU Nvidia V100 Tensor Core, para un total de 16.000. La compañía dijo que también construyó un motor de almacenamiento personalizado, en asociación con Penguin Computing y Pure Storage.
El RSC se basa en 2.000 sistemas Nvidia DGX A100, conectados a través de una red de estructura Nvidia Quantum InfiniBand de 16 Tb/s.
Hubo "algunas lecciones que aprendimos y las incorporamos en la segunda fase del clúster", dijo el ingeniero de software de Meta, Kalyan Saladi. "Lo primero fueron las tasas de fallas. Las tasas de fallas de hardware fueron más altas de lo que esperábamos, y esto nos obligó a crear mejores mecanismos de corrección de detección para garantizar un clúster estable y confiable y ofrecer una experiencia perfecta a nuestros investigadores. A continuación, nuestro tejido: uno de las estructuras IP planas más grandes del mundo, especialmente a esta escala, nos obligó a realizar un trabajo pionero e innovador para encontrar los cuellos de botella en el rendimiento, ajustar y mantener el rendimiento del clúster durante un largo período de tiempo. Y estas lecciones se incorporaron sobre cómo trajimos el resto del grupo en la fase dos".
La empresa también facilitó que los equipos ejecutaran varios proyectos en el RSC al mismo tiempo.
"¿Por qué construir un Super Cluster personalizado en lugar de utilizar la tecnología de centro de datos existente que Meta ha implementado en todo el mundo?" preguntó Saladí.
"Realmente se trata de comprender y darse cuenta de las demandas únicas que el entrenamiento de IA a gran escala impone a la infraestructura. Esto se traduce en nuestra necesidad de controlar los parámetros físicos", dijo Saladi.
"Lo primero es la tecnología de enfriamiento. El enfriamiento basado en el flujo de aire no cumplía con la marca para el entrenamiento de inteligencia artificial a gran escala para nosotros. Así que tuvimos que optar por el enfriamiento líquido, que era una desviación de los centros de datos de producción de Meta. Dada la densidad del rack, dado la cantidad de GPU que queríamos empaquetar en el edificio del centro de datos, esto significó que los requisitos de energía se desviaron significativamente nuevamente de la configuración de producción. Pero hay un aspecto más importante, y es la red back-end plana especializada. Esta es una red de baja latencia y alto ancho de banda con restricciones en los parámetros físicos de hasta dónde puede distribuir estas GPU. Cuando juntó estos tres, tuvimos que tomar la decisión de que necesitábamos un clúster personalizado".

{kind=link}
{kind=link}
{kind=link}
{kind=link}
Chips de meta
Si bien su primera incursión en los semiconductores de IA no salió según lo planeado, Meta espera construir su propio chip ( similar al TPU de Google , Trainium de AWS y Athena de Microsoft).
El chip Meta Training and Inference Accelerator (MTIA) espera, como sugiere su nombre, manejar ambas cargas de trabajo de IA. El semiconductor se basa en el nodo de proceso de 7 nm y lo fabrica TSMC.
Funciona a 800 megahercios, mide unos 370 milímetros cuadrados y tiene un pequeño presupuesto de energía de 25 vatios. Proporciona un cálculo de precisión de 102 tops of integer (8 bits) o 51,2 teraflops de cálculo de precisión FP16.
Amin Firoozshahian, científico de investigación de infraestructura de Meta, dijo: "Es un chip que está optimizado para ejecutar las cargas de trabajo que nos preocupan y que se adapta específicamente a esas necesidades".
Está diseñado en particular para PyTorch, un marco de aprendizaje automático de código abierto lanzado inicialmente por Meta. Además de anunciar el nuevo chip, la compañía detalló PyTorch 2.0.
Además del MTIA, la empresa ha desarrollado el Meta Scalable Video Processor (MSVP).
"MSVP procesa el video nueve veces más rápido que los codificadores de software tradicionales: la misma calidad de video con la mitad de energía", dijo Harikrishna Reddy, gerente líder técnico del proyecto.
"MSVP sube el listón en cuanto a calidad de cambio de tamaño de cuadro, calidad de codificación de video, y somos los primeros en la industria en admitir métricas de calidad objetivas en hardware. Por lo tanto, para cada codificación de video que hacemos, también calculamos un puntaje de calidad utilizando métricas estándar como SSIM, PSNR o MSSIM. Y luego usamos este puntaje de calidad para indicar cómo se percibirá este video cuando un usuario lo vea en el video. Imagine hacer esto a escala en miles de millones de videos".