
Cuando Uptime Institute preguntó recientemente a más de 300 gerentes de centros de datos cómo la pandemia cambiaría sus operaciones, una respuesta quedó clara: dos tercios esperan aumentar la resistencia de sus centros de datos centrales en los próximos años. Muchos dijeron que esperaban que sus costos aumentaran como resultado.
El motivo es claro: la pandemia, o cualquier otra futura, puede significar operar con menos personal y posiblemente con cadenas de suministro y servicio interrumpidas. El monitoreo remoto y el mantenimiento preventivo ayudarán a reducir la probabilidad de un incidente, pero las máquinas siempre fallarán. Tiene sentido reducir el impacto de las fallas aumentando la redundancia del sistema.
Pero incluso antes de la pandemia, había una tendencia hacia niveles más altos de despidos. Como se muestra en la figura siguiente, aproximadamente la mitad de los que participaron en la encuesta global de proveedores, diseñadores y asesores de Uptime Institute 2020 informaron que sus clientes han aumentado los niveles de redundancia en los últimos tres a cinco años.
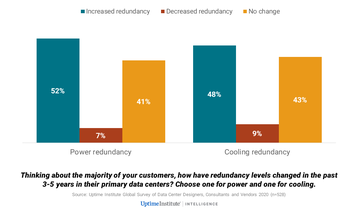
¿No resolvió la nube el problema de la interrupción?
Esta tendencia puede parecer poco sorprendente para algunos, pero no era del todo predecible. El crecimiento de la nube ha ido acompañado de un uso mucho mayor de zonas de disponibilidad regional y resiliencia multisitio. En teoría, al menos, estos reducen sustancialmente el impacto de las interrupciones de las instalaciones en un solo sitio, porque el tráfico y las cargas de trabajo pueden desviarse a otros lugares. Respaldados por esta capacidad, algunos operadores (Facebook es un ejemplo) han procedido con niveles más bajos de redundancia de lo que era común en el pasado (ahorrando así costos y energía).
Sin embargo, el uso de zonas de disponibilidad ha tenido sus propios problemas, y los problemas de redes y software a menudo causan interrupciones en el servicio. Y la pérdida de un centro de datos coloca inmediatamente la demanda de capacidad y tráfico en otros, lo que aumenta los riesgos. Por esta razón, incluso los grandes proveedores de nube y los operadores de aplicaciones de Internet administran en su mayoría instalaciones de mantenimiento simultáneo, y es común que estipulen que los socios de colocación tengan instalaciones de nivel N + 2.
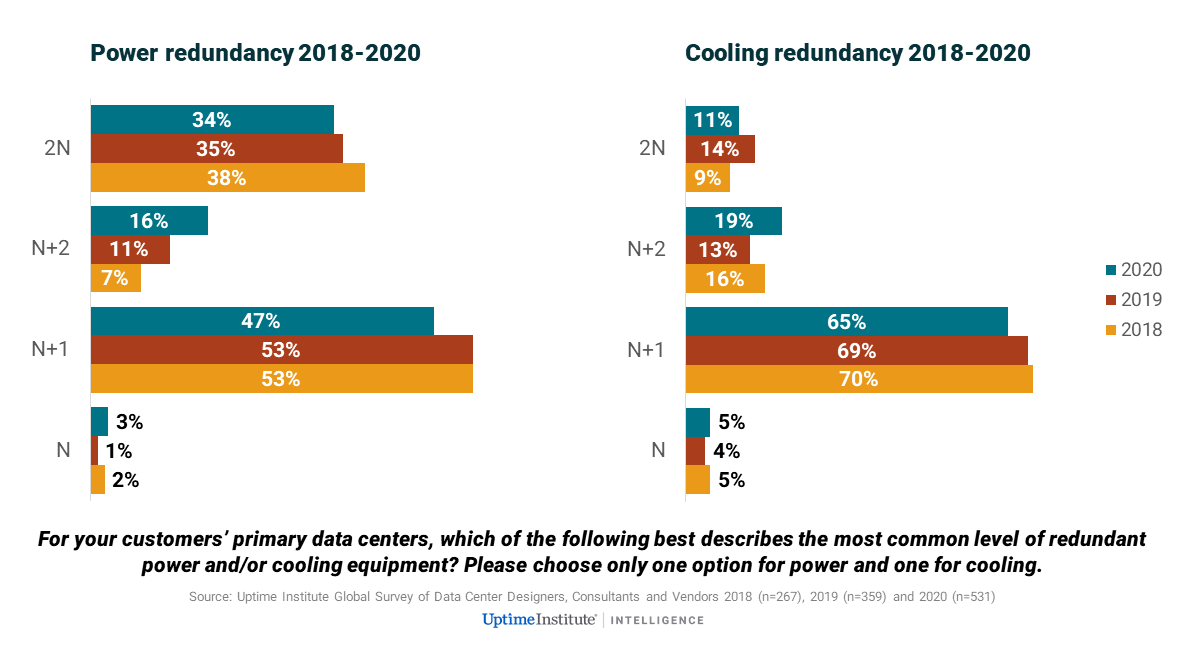
Con una variedad de opciones, el cambio general hacia una mayor resiliencia sigue siendo lento y bastante matizado, y los diseñadores prefieren principalmente configuraciones N + 1 o N + 2, de acuerdo con las necesidades del sitio y del negocio y, a menudo, de acuerdo con la creatividad de la empresa. En general, en realidad hay una disminución marginal en la cantidad de centros de datos que son 2N, pero un cambio constante de tres años de N + 1 a N + 2, no solo en energía, sino también en enfriamiento (ver figura a continuación). También hay un aumento en el uso de zonas de disponibilidad activa-activa, como se discutió en nuestro informe reciente Encuesta global de centros de datos 2020 del Uptime Institute.
{kind=link}
{kind=link}
{kind=link}
Criticidad progresiva
Los patrones de demanda y la creciente dependencia de TI explican en parte estos niveles más altos de redundancia / resiliencia. El nivel de resiliencia necesario para cada servicio o por cada cliente viene dictado por los requisitos comerciales, pero no se fija en el tiempo. La creciente criticidad de muchos servicios de TI destaca la importancia de mitigar el riesgo mediante una mayor resiliencia. La “criticidad progresiva”, una situación en la que la infraestructura y los procesos no se han actualizado o actualizado para reflejar la creciente criticidad de las aplicaciones o los procesos comerciales que admiten, puede requerir actualizaciones de redundancia.
Uptime Institute espera que los operadores hagan un mayor uso de la resiliencia distribuida en el futuro, especialmente a medida que se diseñan más cargas de trabajo utilizando arquitecturas de nube o microservicios (las cargas de trabajo son más portátiles y las instancias se copian más fácilmente). Pero no hay indicios de que esto esté disminuyendo la necesidad de resistencia a nivel de sitio. El software que ejecuta estos servicios distribuidos suele ser opaco, complejo y puede ser propenso a errores de programación o configuración. Los datos de interrupciones anuales muestran que este tipo de problemas están proliferando. Además, las fallas de cualquier componente importante pueden producirse en cascada, lo que dificulta y hace que la recuperación sea costosa, con datos y aplicaciones sincronizados en varios sitios.
La tendencia por ahora es clara: una mayor resiliencia en todos los niveles es el enfoque menos riesgoso, incluso si significa algún gasto adicional y duplicación de esfuerzos.