The world of data centers is full of Intel and Nvidia chips, and this doesn’t sit well with AMD.
The company has struggled with its dense server business, which was shut down last year, and has yet to make a significant impact on the data center market, but it believes it has an opportunity to change the status quo.
More data, and the increasing popularity of machine learning tools to handle that data, requires data centers to embrace heterogeneous computing, AMD believes, and it insists it is best prepared to handle that shift.

Always making data
“Today people have dozens of devices that are connected,” AMD’s CEO Dr Lisa Su said at a press-only event attended by DCD. “So this is pretty exciting.”
“But what’s even more exciting is what’s going on the data center. When we look at that, we actually see both a problem and an opportunity. The problem is, now you have tens of billions of devices that are connected, generating data that you really can’t use, you really can’t do things with, because our systems are not sophisticated enough today for that.”
“So with all of this data, the data center must change. It’s certainly started over the last few years, but what we’re seeing is that it’s accelerating over the next few years. And this is the sort of evolution that we see, and you’ll see in some of the products that we’re putting out over the next couple of years.”
The fact that the amount of data we produce is expanding is obvious. How fast, and across how many platforms, however, is up for debate. Ericsson previously said that 2020 would see 50 billion connected devices, IHS now thinks it will be 17.6 billion, while Gartner believes it will be 6.4 billion (excluding smartphones, tablets and computers), and International Data Corporation predicts 9 billion (also limited to IoT devices).
So what does AMD think will be required to handle all of those devices and their data? “It’s really about machine intelligence. That’s what’s next,” Su said.
“And machine intelligence involves taking all of that data from the 50 billion+ devices, and figuring out how to use that in a reasonable way, how to use that in a useful way so that we can become smarter.”

According to Su, the thing to note about this data is that it comes in all shapes and sizes.
“You’re either talking about text, or video, or audio, or other aspects of data. With all of this different data, you really are in a heterogeneous system. And that means that you need all types of computing to satisfy this demand. You need CPUs, you need GPUs, you need accelerators, you need ASICs, you need fast interconnect technology. All of this is necessary, and the key to it is a heterogeneous environment, a heterogeneous computing architecture.”
The term ’heterogeneous computing’ refers to systems that use more than one kind of processor or core with the aim of serving all the various needs a modern workload might have. “We’ve actually been talking about heterogeneous computing for the last ten years,” Su said. “This is the reason we wanted to bring CPUs and GPUs together under one roof.”
Back in 2013, we covered AMD’s quest to bring heterogeneous computing to servers. The company planned to launch the ’Kaveri’ product line for desktops, notebooks, embedded chips and data center systems. For servers, AMD marketed Kaveri as the Berlin Accelerated Processing Unit, which it called the “world’s first Heterogeneous System Architecture (HSA) featured server APU”.
Behind the Berlin push stood Andrew Feldman, founder and CEO of SeaMicro, who was bullish about AMD’s chances of taking on Intel. But in 2014, Feldman left the company, saying “the SeaMicro group at AMD is stronger than ever, and we have our processors lined up.” The division was shut down a year later, with Berlin no longer expected on sale.
AMD believes that due to recent shifts in the marketplace, history will not repeat itself. Su said: “We were doing this when people didn’t quite understand why we were doing this, and then we were also learning about what the market. But it’s absolutely clear now that in this machine intelligence era, we need heterogeneous computing.”
She continued: “AMD is the only company in the industry that can enable true, high performance heterogeneous applications. We invested in the Zen architecture for four years to create the payoff that we’ve seen in 2017, to have a truly modern CPU. We invested in Radeon, and we’re continuing to double down on Radeon.
“And the other thing that’s extremely important, and I think differentiates AMD significantly, is that we’re not just about us. When we talk about connecting CPUs and GPUs together in a high performance system, we’re going to do that with an open software computing platform. And we’re going to do that with an open interconnect, interacting with the industry. And this is really what we believe is the way that next generation data centers and the machine intelligence era are going to be successful.”
The GPU

“Between when I was in grad school and now, there were those of us that were cynical and rolling eyes at AI and neural nets, while some people continued advancing algorithms,” Raja Koduri, SVP and chief architect of Radeon Technologies Group said.
“And it also happened, without our knowledge, that the GPUs that we were building for you guys to play games, had enough compute to solve these complex algorithms. So today we are actually able to train these things for neural nets in a very effective way.”
Koduri is right - GPUs have been embraced by the machine learning community. But the GPUs they have embraced have primarily been made by Nvidia, with its Pascal Titan X and the extended family of Tesla accelerators - all with CUDA deep-learning programs, supported by Nvidia’s cuDNN machine learning libraries.
AMD, which recently inked deals with Google and Alibaba to supply them with GPUs (they also use Nvidia), thinks its latest product will change all of this.
The company calls it ‘Radeon Instinct,’ a hardware and software stack built around the Radeon Open Compute Platform (ROCm, previously known as the Boltzmann Initiative). “This is is actually bigger than a brand for us,” Koduri said. “This is a completely new initiative.
“We are going to address key verticals that leverage a common infrastructure. The building block for this infrastructure is our hardware class, we call it the Radeon Instinct hardware platform, and aboard that we have completely open source Radeon Open Compute software platform. And on top of that we’re building optimized machine learning frameworks.
“Cloud and hyperscale are our first priority, but we have engaged in some financial services, energy, life sciences, and automotive.”
The hardware aspect of Radeon Instinct consists of three new passively-cooled accelerators, the MI6, MI8 and MI25.
The Radeon Instinct MI6, designed for inference work in mind, uses a Polaris GPU with 16GB of RAM to deliver up to 5.7 Tflops of FP16 or FP32 throughput and 224 GB/s of memory bandwidth.
Designed for both inference and other HPC workloads, Radeon Instinct MI8 packs a Fiji GPU with 4GB of HBM RAM to deliver 8.2 Tflops of FP16 or FP32 throughput and 512 GB/s of memory bandwidth.
Less is known about the Radeon Instinct MI25, as it comes with AMD’s upcoming next-generation Vega GPU, which has yet to be fully revealed. The MI25 is designed for the difficult task of AI training.

“Training takes a lot of GPU computing horsepower, it takes hours today,” Koduri said. “It can take a single GPU of around 6-8 Tflops several hours depending on dataset size and all of this stuff. Inference is a lot faster. So the GPUs are used for both these tasks, and our strategy is to address both of these.”
But “hardware is just half the problem for this market,” he added. “If hardware was the most important thing, AMD GPUs have way, way more compute performance over the last 10 years than any other GPU, we pack more compute per millimeter squared, more compute per dollar than our competition did, I think, all the way since 2005. That’s eleven years.”
On the software side, AMD’s ROCm can accelerate common deep learning frameworks like Caffe, Torch 7, and TensorFlow. Another significant product announced by AMD is MIOpen. “It is a deep learning library, fully open source, optimized for Radeon Instinct. With MIOpen, we got three times speed up of machine learning programs.”
In addition, Radeon Instinct accelerators will support hardware virtualization using AMD’s MxGPU feature.
“Our competition segregates all of these markets,” Koduri said. “You want to get virtualization? You have to buy Grid; you want to get AI? You get Tesla. No, our customers want both together, and we’re providing the virtualization capabilities across the full stack.”
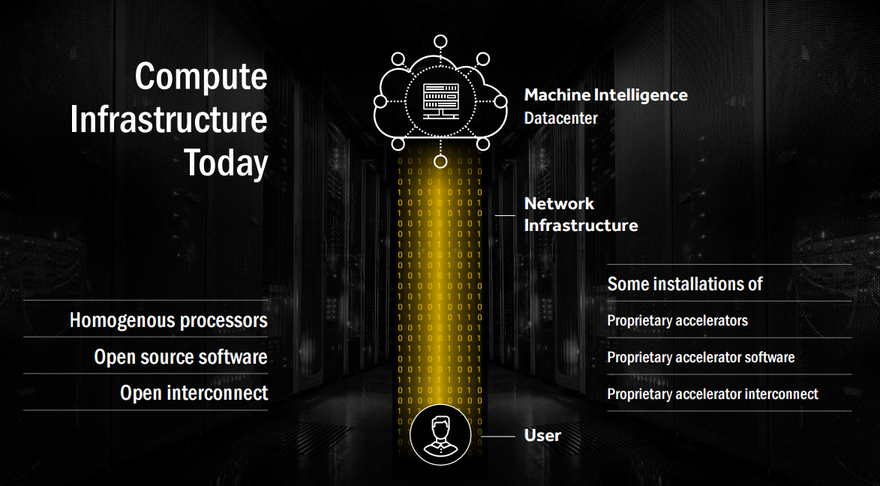
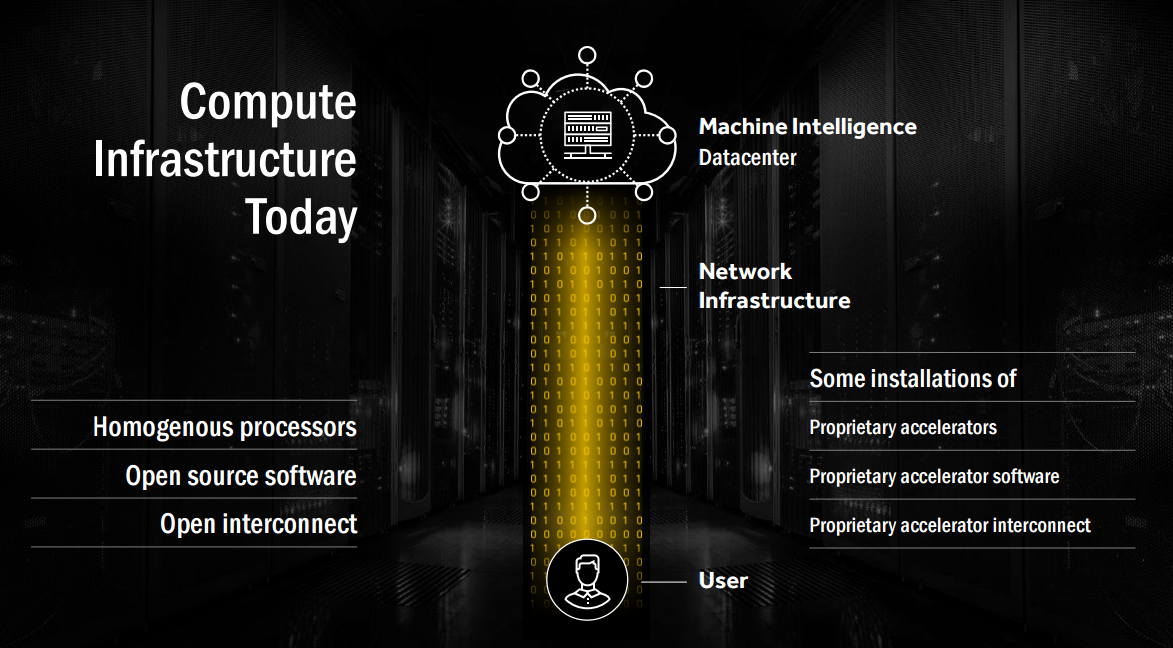
Koduri also believes that the competition is wrong about choosing proprietary over open source when it comes to accelerators: “If you look at the compute infrastructure today, the other thing is that actually they’re predominantly homogeneous processes built on Linux. And proprietary accelerators, proprietary accelerator software, and proprietary accelerator interconnect, are kind of beginning to make waves in the data center. But we don’t believe that’s going to last.
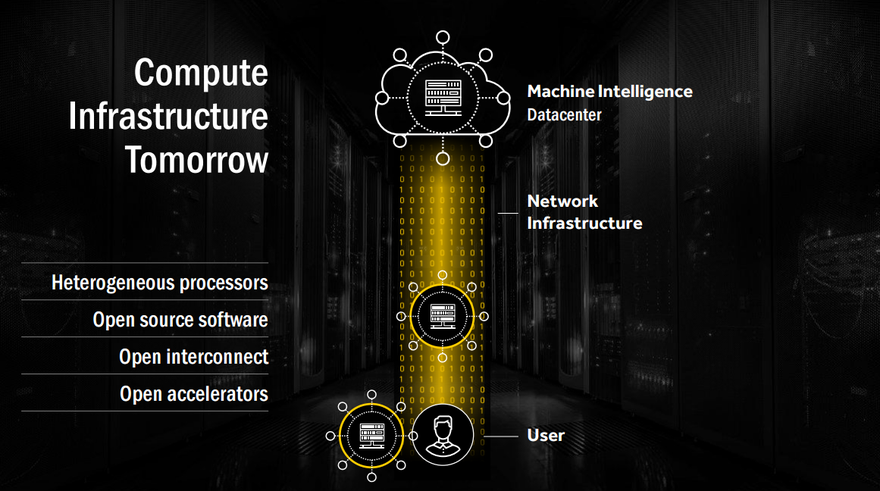
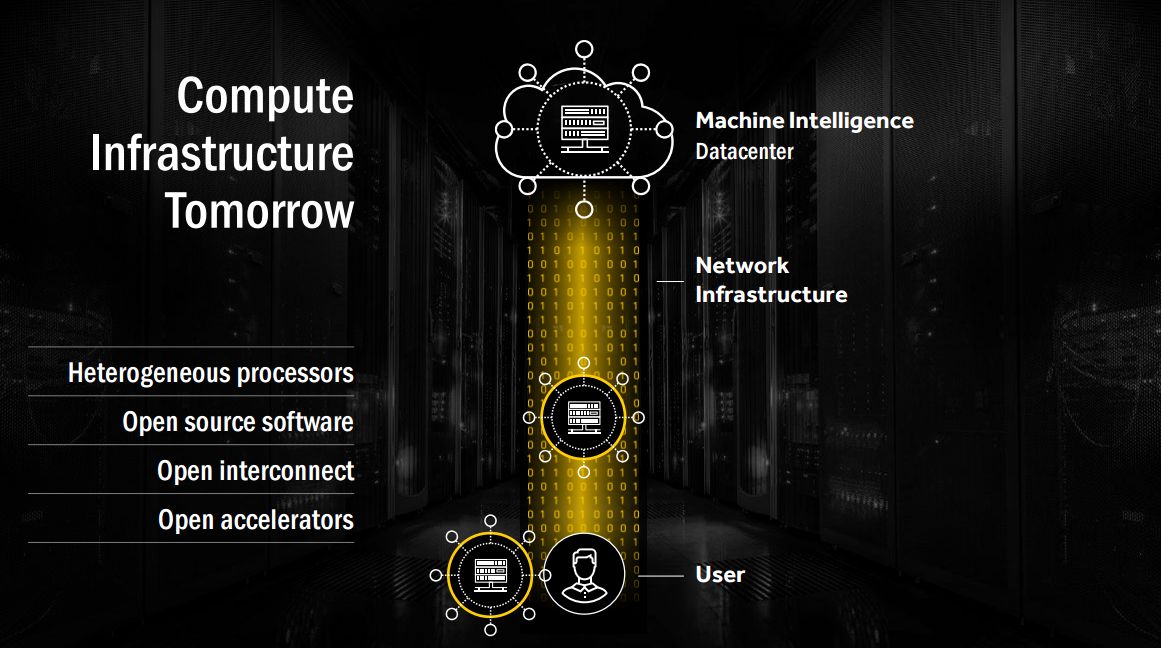
“It’s about heterogeneous processors, that’s what our ecosystem wants, and they want the entire software to be open sourced. That is super important for the data center. Imagine the data center of today without Linux. Open interconnect is also very, very important. And open accelerators - accelerators whose instruction sets are open so that people can build their own custom compilers, custom software infrastructure. That’s tomorrow’s compute infrastructure.”
Compiler technology is also one of the reasons Koduri remains skeptical about start-ups that build GPU hardware. “There are many start-ups, and I work with several of them to see if we should integrate some of the technology on the GPU side,” he told DCD. “But the fundamental roadblock comes to be when we engage with them and say ‘okay, do you have a compiler?’, and they’re like ‘well, we just hired a small team, and they’ll write a compiler for our architecture.”
“And we know how long it took for us to get to the compiler we have today. It actually started with writing shader compilers for VX8.1 to today before we had like a hundred people compiler team and a full-fledged compiler base. It’s actually really hard to develop compiler technology for new architectures.”
Koduri was equally lacking in enthusiasm when it came to the subject of hardware that’s being developed, or at least partially developed, by cloud companies themselves, such as Google’s TPUs, Microsoft’s FPGAs, and Amazon’s chips acquired with purchase of Annapurna Labs in 2015.
He told DCD: “It’s amazing that they can afford to build whatever silicon they do, but everybody says they’re building silicon, and they’re actually building an FPGA as proof-point, because building silicon is a super-expensive process and you need high volume for it to make sense, to say ‘I’m going to make my own chip.’ How many of those are you going to use or sell? So there’s a scale issue. It ends up with people like us, Nvidia, Intel and we make a piece of die, we sell millions of them, we have plenty of use cases.
“The second thing is, like I said, we believe that for the next generation machine intelligence, it’s going to be heterogeneous processors. So it’ll be programmable CPUs, programmable GPUs, FPGAs, and special function stuff. We believe that the interconnect is a very important thing, that how these things all work with each other is going to be super important.”
Koduri added: “If you look at the data center installations, the GPU for them is actually useful beyond machine intelligence, so they are doing hosted gaming, hosted professional applications, which is huge these days. So if they have, say, 100,000 GPUs sitting in a data center, they don’t want them going to waste. In fact, they don’t want any of that silicon going to waste, so if you have some special purpose thing, and you build a huge data center off it, and it’s not being used, it’s not a good thing. That’s the problem for special function stuff, they don’t have other uses.”
The CPU
To bring about this vision of “connecting CPUs and GPUs together in a high performance system” like Su hopes to achieve, requires a CPU with heterogeneous computing in mind.
The second quarter of 2017 will see the release of the Zen ’Naples’ Platform (NB: the consumer focused version of Zen has been renamed Ryzen, but the server version is still called Zen). Specs that leaked earlier this year point to 32 Zen CPU cores running SMT (Simultaneous Multi Threading) to allow 64 threads, and a massive 512MB L3 Cache.
“This is a platform optimized for GPU and accelerator throughput computing,” Koduri said, announcing the Radeon Instinct with Zen ’Naples’ Platform.
“It will lower the system cost for heterogeneous computing dramatically. It’s the lowest-latency architecture, it has the peer-to-peer communication leveraging that large box support so that you can have many, many GPUs attached to a single node. That’s what our customers want. Not one GPU, not two, but four, eight, sixteen.
“And this tiny form factor means that the footprint that we can get in the data center is quite exciting.”
The result
To accompany the Radeon Instinct reveal, AMD also demonstrated three servers to house its new tech.
On the small side we saw the Super Micro SYS 1028GQ-TRT, a 1U dual Xeon box with three PCIe3 16x slots, all filled with Instinct cards. Next up was Inventec’s K888 G3 with Radeon Instinct, a 2U box with Instinct GPUs and two Haswell or Broadwell Xeons that achieves 100 Tflops.
But the most impressive piece of tech was the Inventec PS1816 Falconwitch. The 400 Tflop beast packs 16 Instinct MI25 cards, along with an undisclosed number of CPUs in a 2U server. The CPUs are not named, but are thought to be Zen-based Naples.
The Falconwitch can be combined to form the Inventec Rack with Radeon Instinct, creating a 3 Petaflop machine with 120 Instinct GPUs.
All of this is just the beginning, Koduri told DCD, in changing the data center.
“I think we’ll start seeing some interesting approaches [to edge data centers] in the next couple of years, because the infrastructure, the technology’s all there today. As soon as you see something like ‘hey I can have a petaflop data center in something tiny,’ then you start thinking about the fact that you could put that on your cell tower. That petaflop compute - why should it be a thousand miles away from me?
“There are no good reasons any more.”
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}