
Moving critical applications and services to the cloud brings unprecedented power to IT teams who no longer have to worry about building and maintaining infrastructure. At the same time, cloud computing introduces a solid dose of unpredictability due to the sheer complexity of the Internet and cloud connectivity. We get reminded of this reality on a reasonably regular basis when outages occur in cloud or other service providers.
On June 2nd between 12pm and 12:15pm PDT, ThousandEyes detected a network outage in Google’s network that impacted services hosted in some of the US regions of Google Cloud Platform. The outage lasted for more than four hours and affected access to various services including YouTube, G Suite and Google Compute Engine. The following is a recap of what we saw and how you should think about resiliency and visibility as you move into the cloud.
Early Indicators
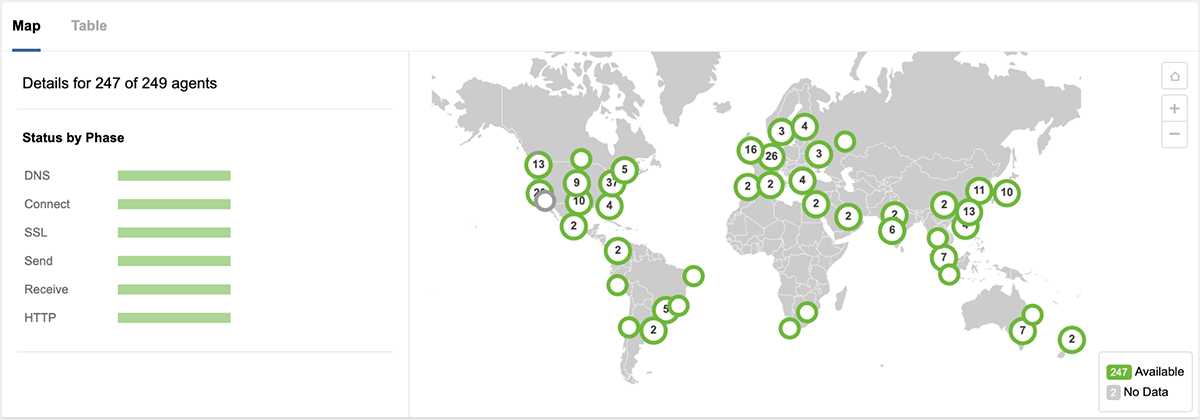
ThousandEyes started to see both user-level impacts and macro network impacts from the Google Cloud outage starting shortly after 12:00pm PDT on June 2nd, right around the time that initial social media and posts on downdetector began. Figure 1 shows the disruption as seen from 249 global ThousandEyes Cloud Agents in 170 cities that were monitoring access to content hosted in a GCE instance in GCP us-east4-c, but served dynamically via a CDN edge network. Users accessing other GCP-hosted services would have started to feel the impact of the outage at this time.
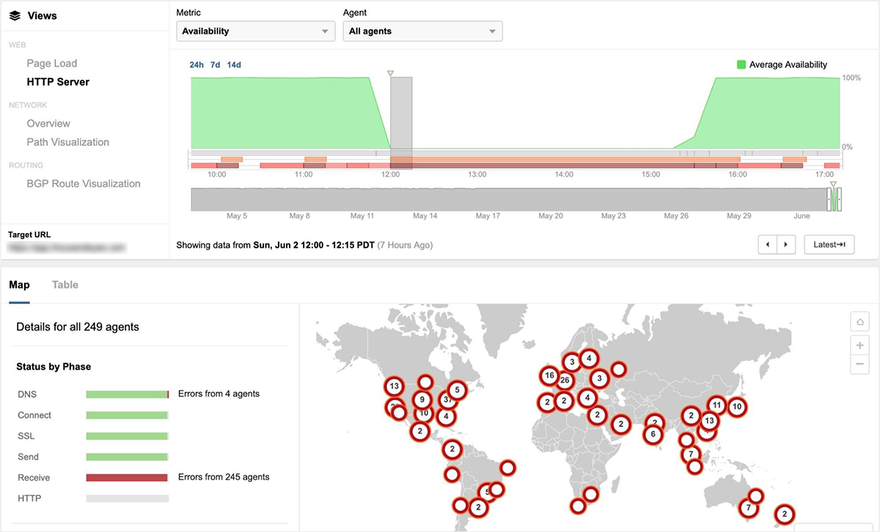
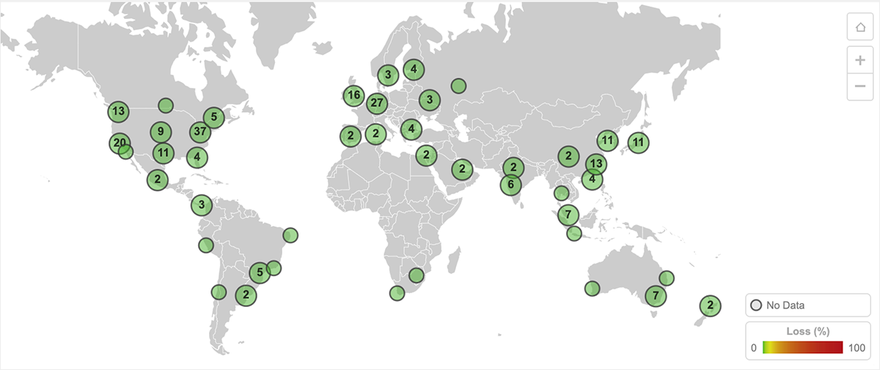
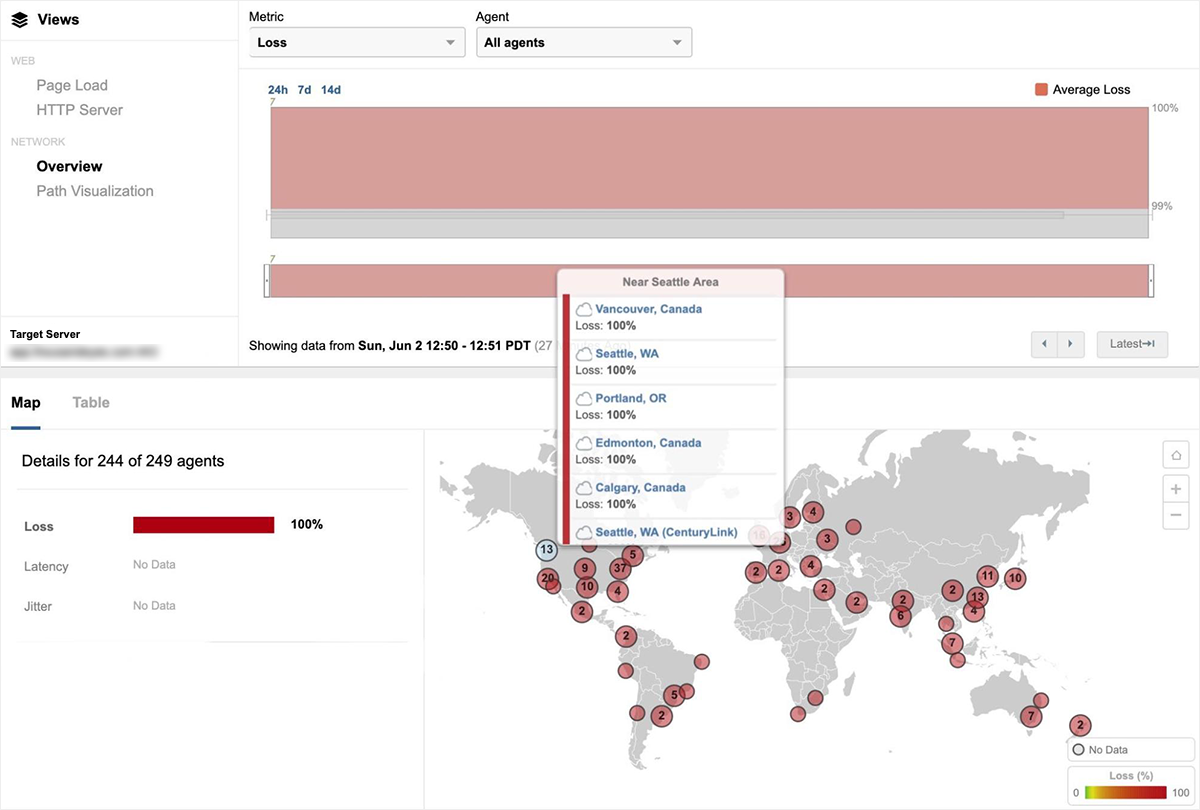
Figure 2 shows the extent of packet loss - 100 percent - for users attempting to reach a site hosted in GCP us-west2-a from locations around the globe.
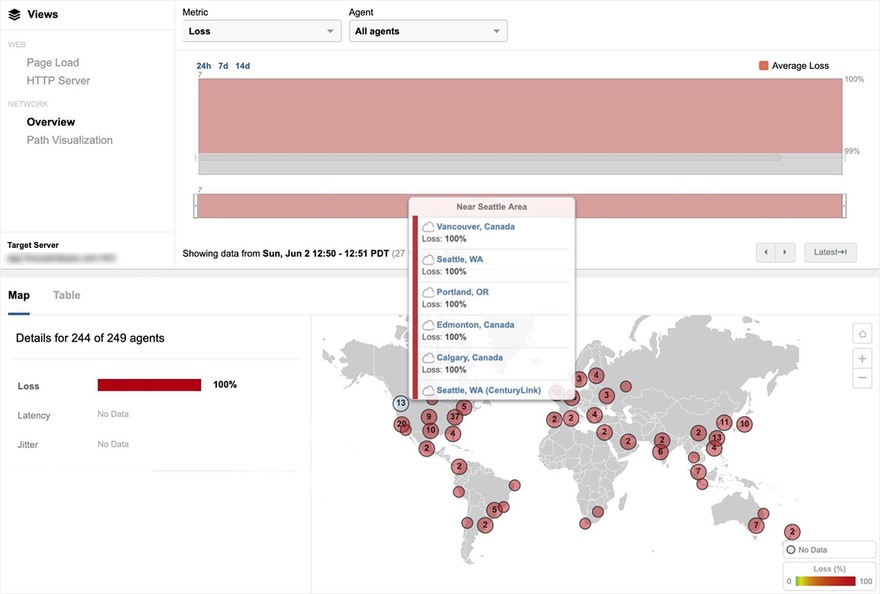
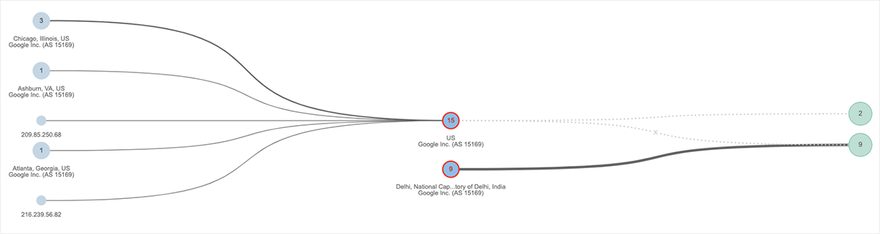
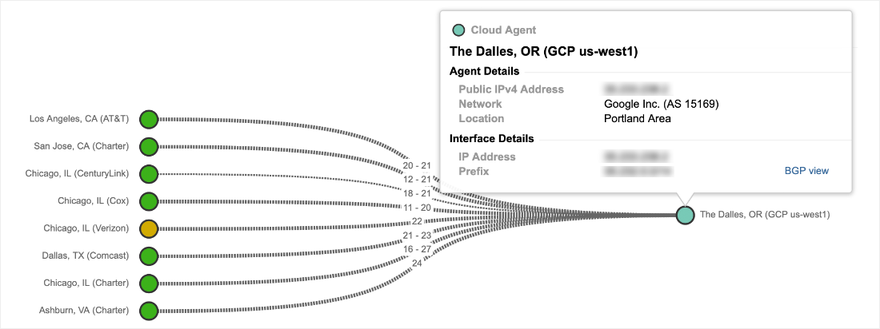
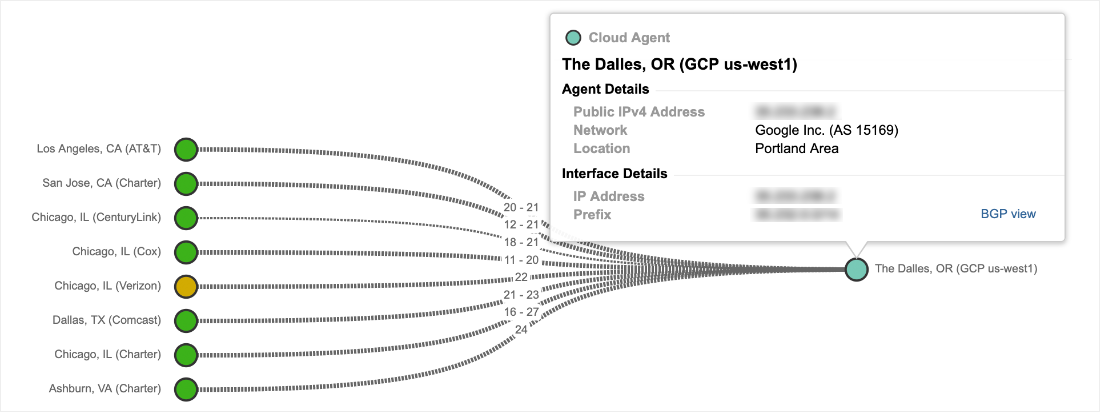
At a macro level, we also were also able to see connectivity and packet loss issues that impacted Google network locations in the eastern US, including Ashburn, Atlanta and Chicago. As an example, Figure 3 shows a topology mapping of Google network locations. The light blue nodes on the left show the number of source interfaces per location attempting to reach two Google-hosted domains located on the far right.
Between those two points, 15 interfaces located in Google’s network are experiencing heavy packet loss that is preventing traffic from the source interfaces from reaching the services domains. As an interesting side note, the lower portion of the topology in Figure 3 shows evidence of network connectivity issues impacting the Google network in India.
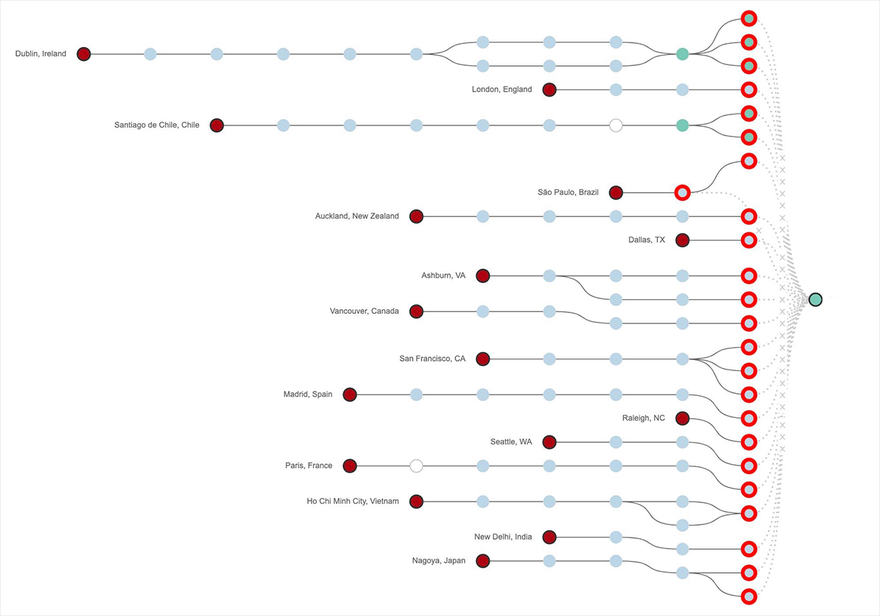
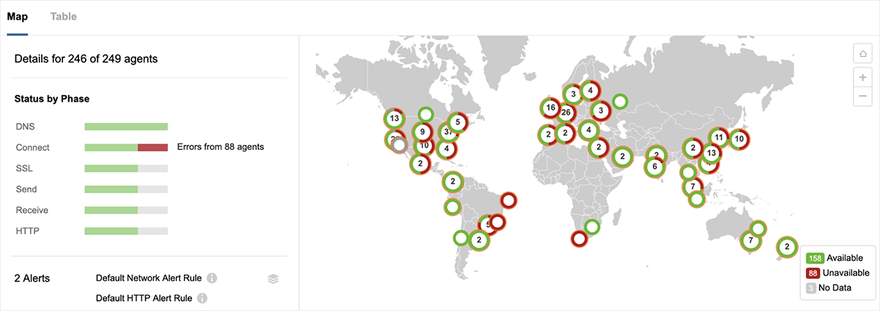
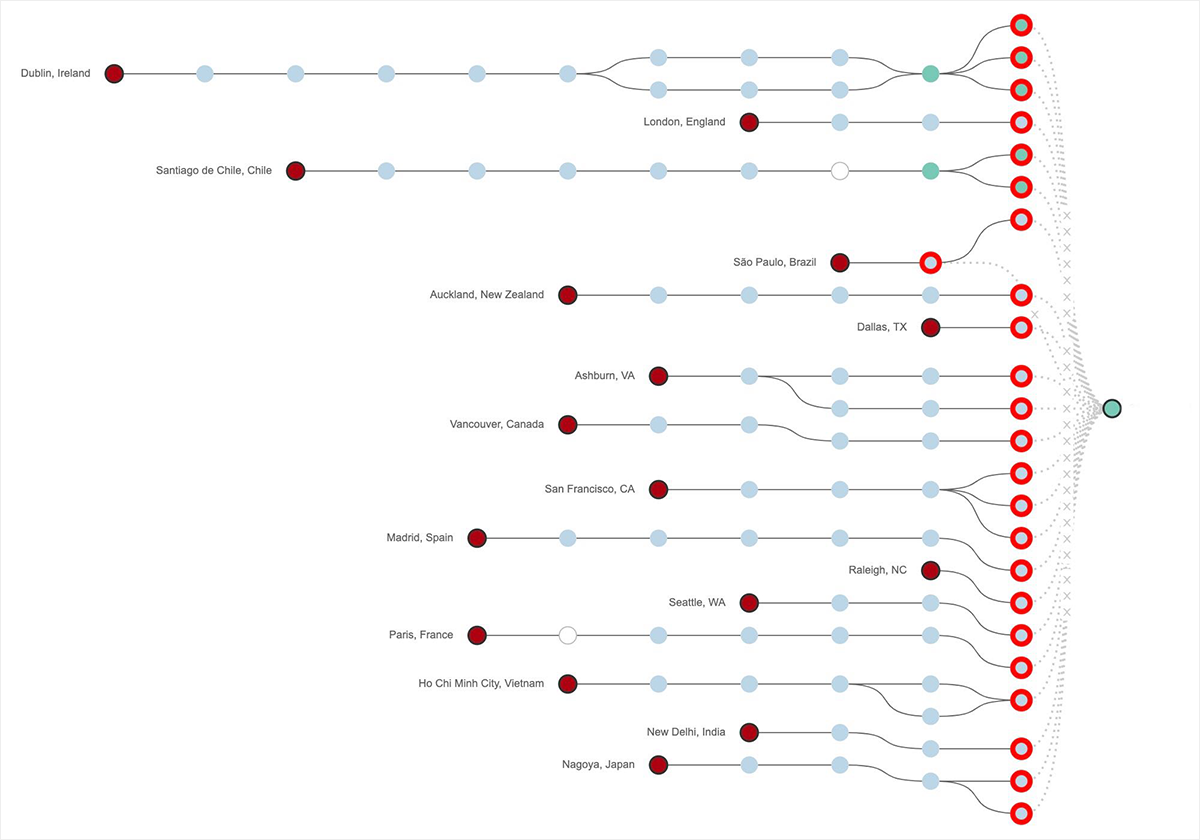
From a connectivity point of view, our Path Visualization showed traffic dropping at the edge of Google’s network, as seen in Figure 4 below. In fact, for 3.5 hours of the 4+ hour outage, we saw 100 percent packet loss for global monitoring locations attempting to connect to a service hosted in GCP us-west2-a. Similar losses were seen for sites hosted in several portions of GCP US East, including us-east4-c.
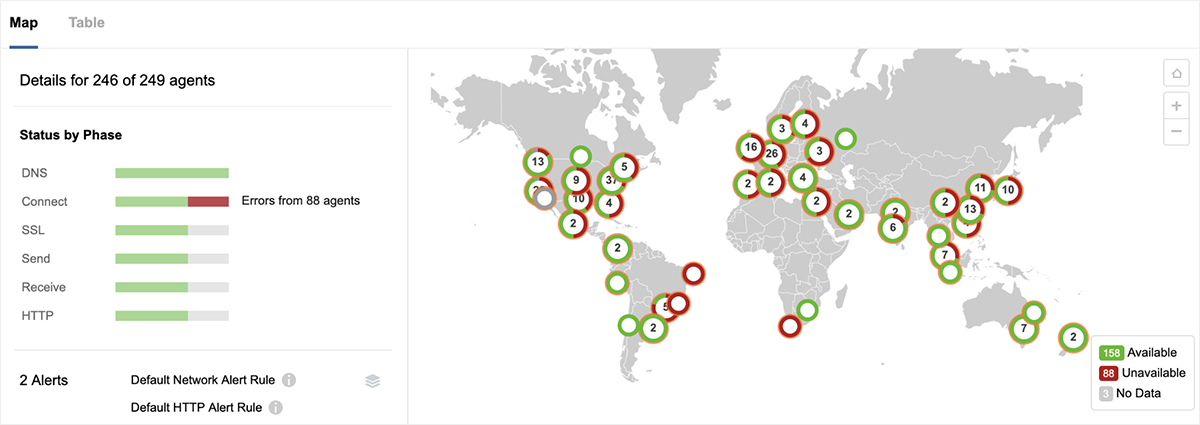
However, the outage was not uniform across the regions impacted. For example, in Figure 5 below, a different service hosted in GCP us-west1 was fully available during the course of the outage.
In fact, most GCP regions were unaffected by the outage, including regions in the US as well as in Europe and elsewhere. For example, Figure 6 shows that the europe-west4 region, which is located in the Netherlands, remained reachable during the outage period. The green status shows that global monitoring agents were encountering little-to-no network packet loss in accessing the region.
Google’s Analysis
Google was aware of the issues early on and announced service impacts on Google Compute Engine beginning at 12:25pm PDT, as seen in Figure 6. They subsequently posted an update at 12:53pm that the service impacts were tied to broader networking issues. By 1:36pm, Google had identified the issue as related to high levels of network congestion in the eastern US, which aligned with the elevated packet loss we started seeing before the announcement (see Figure 2 above).

Service Restoration
Beginning at roughly 3:30pm PDT, we started to see packet loss conditions easing and reachability to Google services improving, as seen in Figure 8, which shows updated status for connectivity to a service in GCP us-west2-a. Reachability continued to improve over the next hour, which we continuously tracked over that period.
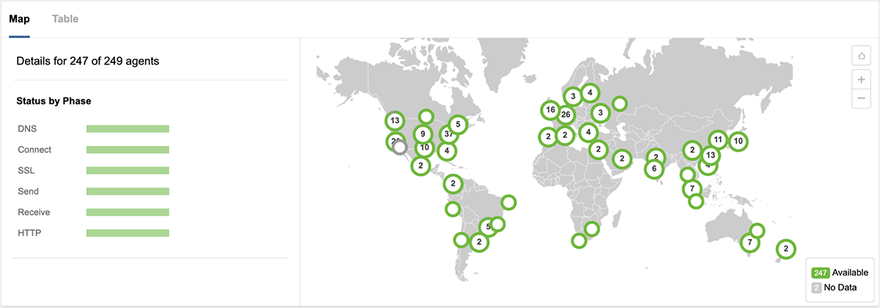
Service finally appeared fully restored by 4:45pm PDT, as seen in Figure 9.
At 5:09pm, Google posted that the network congestion issue was resolved as of 4pm PDT for all impacted users, as seen in Figure 10. They also promised an internal investigation of the issue.

Where do cloud users go from here?
One of the most important takeaways from cloud outages is that it’s vitally important to ensure your cloud architecture has sufficient resiliency measures, whether on a multi-region basis or even multi-cloud basis, to protect from future recurrence of outages. After all, it’s only reasonable to expect that IT infrastructure and services will sometimes have outages, even in the cloud.
The cloud and the Internet are inherently prone to unpredictability because they are massive, complex and endlessly interconnected. The cloud is arguably still the best way to do IT for most businesses today, but it carries risks that no team should be unprepared for.
Given the increasing complexity and diversity of the infrastructure, software and networks you rely on to run your business, you need timely visibility so you can tell what’s going on and get resolution as fast as possible. The good news is you don’t need to have the global infrastructure and an engineering team the size of a FAANG company to see through the cloud and the Internet.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}