
Right now, there is a great deal of excitement about Generative AI (Artificial Intelligence) especially Large Language Models (LLMs). The initial hype surrounding ChatGPT is arguably waning, but it is clear that there is enough technology and academic research for serious developer attention.
Despite the potential of the approach, LLMs come with a range of challenges. These include the well-known issue of hallucinations (making up persuasive falsehoods), but also false logical reasoning (if two shirts take two hours to dry on the line, how long do five shirts take?) and giving the wrong answer when a question is inverted.

Generative AI & the future of data centers: Part I - The Models
A seven-part article on what large language models and what the next wave of workloads mean for compute, networking, and data center design
In addition, there are high costs associated with training an enterprise-use LLM. It is complex to update and maintain them, and it is difficult to conduct audits and provide explanations. Fortunately, these issues can be remedied or palliated.
Knowledge graphs to the rescue
The drawbacks of LLMs can be significantly addressed by supporting them with knowledge graphs built atop modern graph database engines. Strong technical analysts like Redmonk agree: “Enterprises are justifiably worried about the dangers of incorrect information or ‘hallucinations’ entering their information supply chains, and are looking for technical solutions to the problem. Graph databases are one well-established technology that may have a role to play here.”
Let’s see how. A knowledge graph is an information-rich structure that provides a view of entities and how they interrelate. They are a natural fit for graph databases which are well-suited for applications that involve complex, interconnected data with many relationships.
We can express these entities and relationships as a network of assertable facts, that is a “graph” of what we know. Having built such a structure, we can query it for patterns but can also compute over the graph using graph algorithms and graph data science. Doing so can uncover facts that were previously obscured and lead to valuable insights.
You can even generate embeddings from this graph (both its data and its structure) which can be used in machine learning pipelines.
By pairing a knowledge graph with an LLM, four main approaches emerge:
- First, the natural language processing features of LLMs can process a huge corpus of text data. We then ask the LLM itself to produce a knowledge graph. The knowledge graph can be inspected, QA-ed, and curated. Importantly, the knowledge graph is explicit and deterministic about its answers in a way that LLMs are not.
- In the second approach, instead of training LLMs on a large general corpus, enterprises can train them exclusively on an existing knowledge graph. That means they can build natural language chatbots that appear very knowledgeable about a firm’s products and services, and can answer users without risk of misleading hallucinations.
- In a third approach, messages going to and from the LLM can be intercepted and enriched with data from the knowledge graph. On the path into the LLM we can enrich prompts with data from the knowledge graph, while on the way back from the LLM, we can take embeddings and resolve them against the knowledge graph to provide greater depth and context for the answer.
- In a fourth approach, which is active in the research sphere, better AIs can be built with knowledge graphs. Here, an LLM is enriched by a secondary smaller AI, known as a “critic.” The critic looks for reasoning errors in the LLM. In doing so it creates a knowledge graph for downstream consumption by another “student” model. Ultimately, the student is smaller and more accurate than the original LLM since it never learns factual inaccuracies or inconsistent answers to questions, and fictions are largely omitted.
Knowledge graphs with ChatGPT on Microsoft Azure
It’s worth reminding ourselves why we are doing all this work with ChatGPT-like tools. Using Generative AI can help knowledge workers execute queries they want to be answered without having to understand and interpret a query language or build multi-layered APIs. This has the potential to increase efficiency and allow employees to focus their time and energy on more value-added tasks.
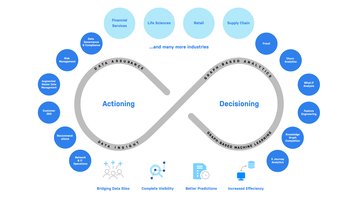
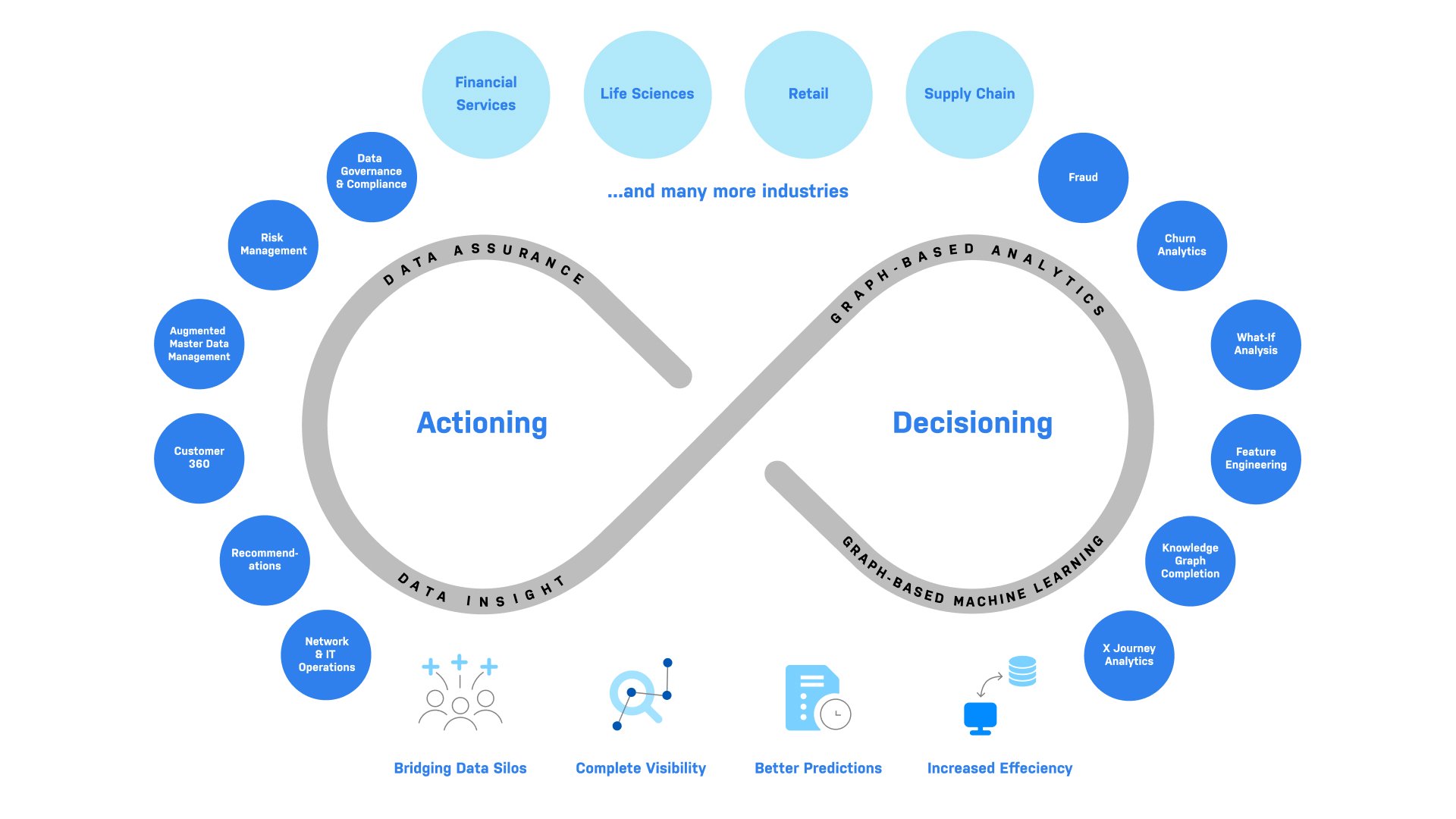
A global energy multinational is already using knowledge graphs with ChatGPT on Microsoft Azure across multiple deployments for its enterprise knowledge hub, for example—integrating data across 250+ subdivisions for better predictive analytics, machine learning workloads, and process automation. Later this year, the company will deliver additional GenAI-based cognitive services to thousands of employee users across vertical domains and personas including Legal, Engineering, and other key departments.
The company’s initial proof of concept is believed to unlock at least $25m in value within three months with graphs and LLMs. Clearly, LLMs and knowledge graphs are a powerful combination—especially if the graph is one to make the data, not the apps, smarter.
It’s also a combination that can empower GenAI to tackle substantial challenges with precision and in ways that business users can trust.
The author is co-author of Graph Databases (1st and 2nd editions, O’Reilly) and Graph Databases for Dummies (Wiley). More detail on this discussion can be found in Building Knowledge Graphs (O’Reilly, published August 2024)



{kind=link}