
Decades before AI became the word on everyone’s lips, I was involved with a project to support the primary data center of the world’s largest retailer.
The CIO proudly showed me a brand new, state of the art computer that was able to approve and process credit card payments in less than a second, helping to prevent fraud while improving customer experience.
This computer’s speed and efficiency were a game changer – computer technology to the rescue! Needless to say, this large box shaped IT technology was now a critical part of that retailer’s ecosystem, and it needed adequate power and cooling to maintain its availability.
Times have indeed changed, as the physical infrastructure needed to support this computer was a simple computer room air conditioner and a UPS in the electrical room. AI may be at the forefront of our industry today, but decades ago it was this machine at the forefront!
Now AI servers present daunting challenges for power and cooling due to their very high heat output and densification.
Technology evolves
By the late 1980s, the industry had moved on from the once popular minicomputers like the one at the large retailer. The computing world shifted to Client Server model Intel x86, IBM PowerPC, or Sun SPARC computers, controlled by Windows or UNIX variant operating systems. The minicomputer industry went away through acquisitions and bankruptcies.
The mid-1990s saw the rise of cloud computing with mainly X86 based servers making up server farms that were the backbone of the cloud. Processors have been evolving since Intel introduced the first commercial microprocessor in 1971.
Intel co-founder Gordon Moore came up with Moore’s Law in 1975 that said – computing power doubles about every two years, while better and faster microchips become less expensive.
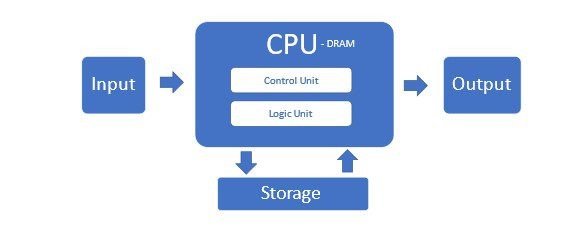
Moore’s Law had an incredible run until recently when physical limits began to limit how many micro transistors could be squeezed onto an affordable CPU. These traditional servers using x86 CPUs comprise the majority of data centers in what’s called the Von Neumann Architecture.
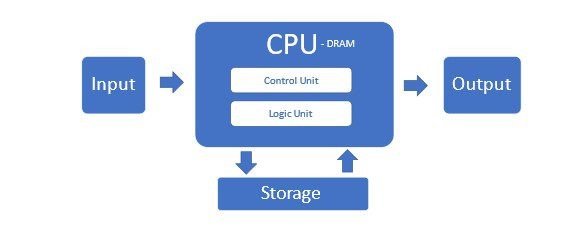
But this architecture is not adequate for AI servers and its clusters. Its suffers because CPUs cannot efficiently process the big data flow and the memory is bottlenecked in this configuration.
New requirements for AI servers
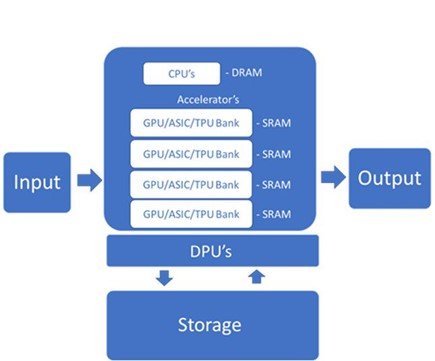
AI servers require special purpose accelerators such as Graphics Processing Units (GPUs) or Application-Specific Integrated Circuits (ASICs) such as Google’s Tensor Processing Units (TPUs) or Huawei’s Ascend 910. These accelerators can handle the high data rates needed for AI model training and inference.
These chips have healthy on chip memory to increase processing speed and efficiency. Within the server, they are managed by CPUs and data is passed using high bandwidth interconnections. Multi-port memories mean you can parallelize reads and writes for faster speed.
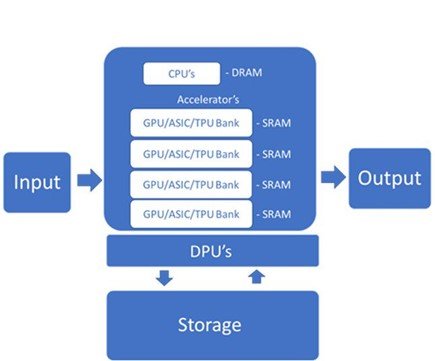
DPUs work with CPUs and GPUs to enhance computing power and the handling of increasingly complex modern data workloads. The Data Processing Unit (DPU) is a relatively new component to the AI server offloads processing-intensive network, storage, and management tasks from the CPU.
Training and inference workloads
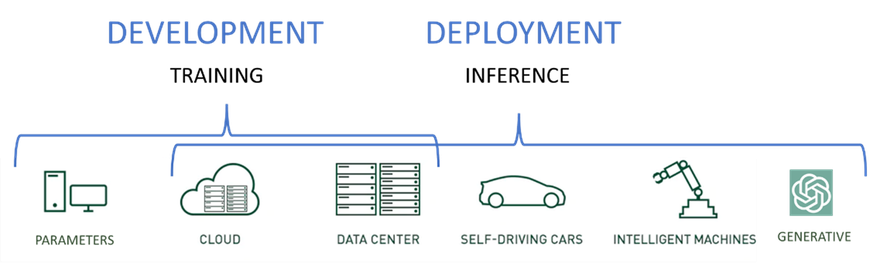
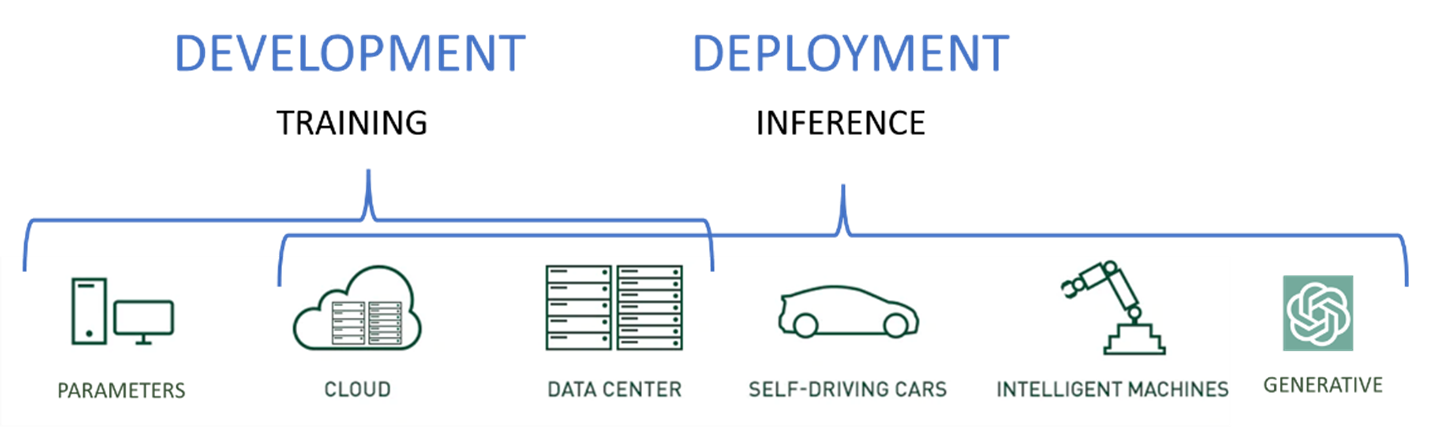
State-of-the-art AI servers run two distinct types of workloads – Training and inference.
- Training workloads: Used to develop initial models and enhance models based on new data and learned information.
- Inference workloads: Use of the models developed during training and predict the outcome based on new data.
{kind=link}
{kind=link}
{kind=link}
While inference models can run on super powerful training servers, they are best located closer to users and data input to increase speed, reduce network clutter, and reduce latency.
Most of the time, inference servers will also run a reduced version of the trained model. Accelerator GPUs are still critical to achieving the business service level objectives SLAs and requirements for inference workloads in most cases.
New white paper 110 on AI servers
The hardware technology needed to support all versions of AI, machine learning (ML), Generative AI (GAI), and Large Language Models (LLM), to name but a few is truly an ecosystem that includes powerful endpoint devices.
Smartphones can input text, images, and even video through powerful, high-capacity networks to the inference servers that run a scaled down version of the trained models that accept input into the model, and return the output that could be a decision, a text description, a picture, or even music.
For a detailed look at the physical infrastructure needed to support this new generation of AI servers and best practices for deployment, Schneider Electric’s Energy Management Research Center has just published our new White Paper 110: The AI disruption: Challenges and guidance for data center design here.
More from Schneider Electric
-

Schneider Electric & Aeven to deliver excess power to Danish grid
Aeven to contribute to Fast Frequency Reserve pool
-

DCD>Talks Sustainability at the Edge with Carsten Baumann, Schneider Electric
Tune into this DCD>Talk from our Silicon Valley event, where we discuss scaling infrastructure at the edge whilst reducing the carbon footprint of distributed IT, with Carsten Baumann, Schneider Electric
-

Sponsored Demystifying data center Scope 3 carbon
Indirect emissions your organization is directly responsible for? The new findings from Schneider Electric helping to demystify Scope 3